class: center, middle, inverse, title-slide # Machine Learning II ## with caret ### Basel R Bootcamp<br/><a href='https://therbootcamp.github.io'>www.therbootcamp.com</a><br/><a href='https://twitter.com/therbootcamp'><span class="citation">@therbootcamp</span></a> ### July 2018 --- layout: true <div class="my-footer"><span> <a href="https://therbootcamp.github.io/"><font color="#7E7E7E">BaselRBootcamp, July 2018</font></a>                                        <a href="https://therbootcamp.github.io/"><font color="#7E7E7E">www.therbootcamp.com</font></a> </span></div> --- <div class="center_text_2"> <span> Recap from Machine Learning I </span> </div> --- # What is machine learning? .pull-left55[ ### Algorithms autonomously learning from data. Given data, an algorithm tunes its <high>parameters</high> to match the data, understand how it works, and make predictions for what will occur in the future. <br><br> <p align="center"> <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/mldiagram_A.png"> </p> ] .pull-right4[ <p align="center"> <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/machinelearningcartoon.png"> </p> ] --- # What is the basic machine learning process? <p align="center"> <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/MLdiagram.png"> </p> --- # Why do we separate training from prediction? .pull-left35[ <br> Just because a model can <high>fit past data well</high>, does *not* necessarily mean that it will <high>predict new data well</high>. Anyone can come up with a model of past data (e.g.; stock performance, lottery winnings). <high>Predicting what you can't see in the future is much more difficult.</high> > "An economist is an expert who will know tomorrow why the things he predicted yesterday didn't happen today." ~ Evan Esar ] .pull-right6[ <p align="center"> <img src="https://raw.githubusercontent.com/therbootcamp/Erfurt_2018June/master/_sessions/_image/prediction_collage.png"> </p> ] --- <br><br> <font size = 6>"Can you come up with a model that will perfectly match past data but is worthless in predicting future data?"</font><br><br> .pull-left45[ <br> <font size=5><hfont>Past <high>Training</high> Data</hfont></font> <br> | id|sex | age|fam_history |smoking | disease| |--:|:---|---:|:-----------|:-------|-------:| | 1|m | 45|No |FALSE | 0| | 2|m | 43|Yes |FALSE | 1| | 3|f | 40|Yes |FALSE | 1| | 4|m | 51|Yes |FALSE | 1| | 5|m | 44|No |TRUE | 0| ] .pull-right45[ <br> <font size=5><hfont>Future <high> Test</high> Data</hfont></font> <br> | id|sex | age|fam_history |smoking |disease | |--:|:---|---:|:-----------|:-------|:-------| | 91|m | 51|Yes |TRUE |? | | 92|f | 47|No |TRUE |? | | 93|m | 39|No |TRUE |? | | 94|f | 51|Yes |TRUE |? | | 95|f | 50|Yes |FALSE |? | ] --- # Overfitting 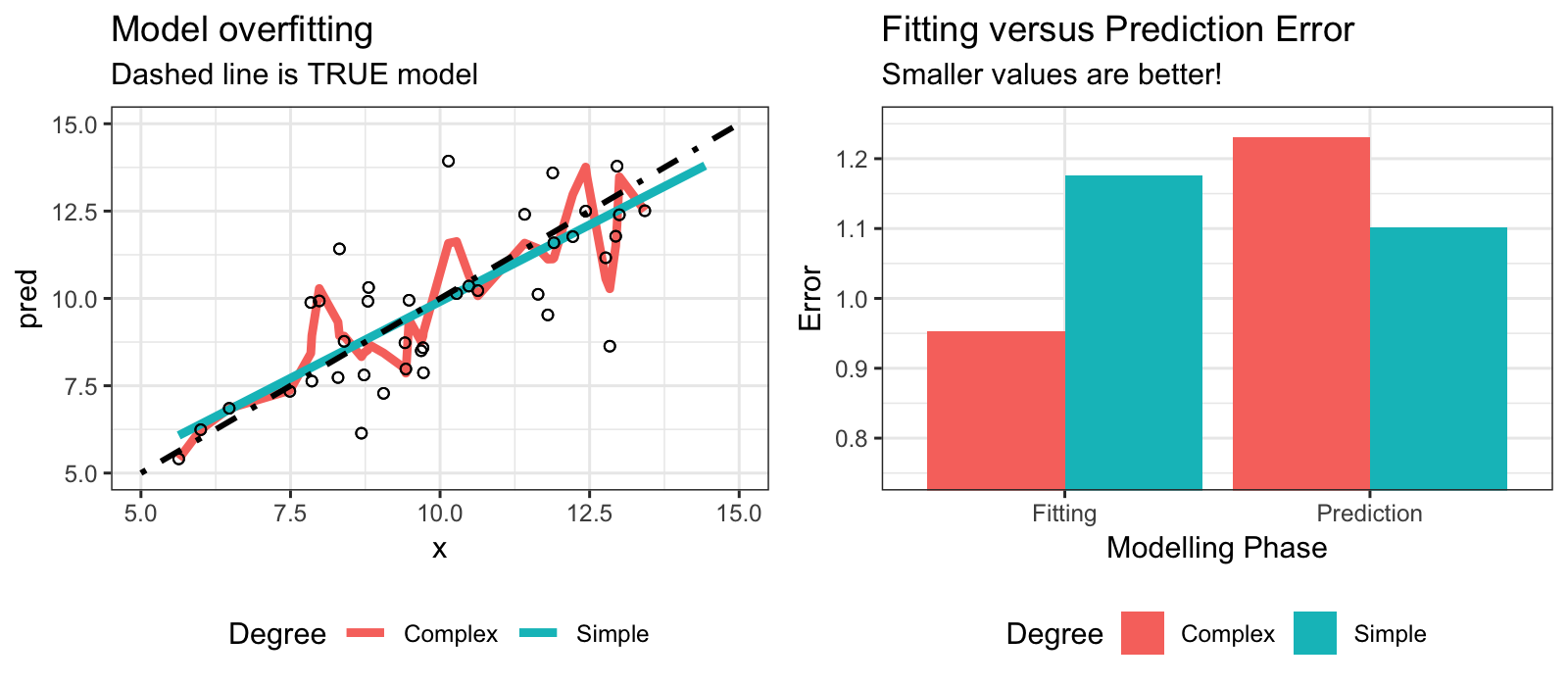<!-- --> --- # Optimizing model parameters with cross validation .pull-left5[ ### Two types of parameters Most ML models have two types of parameters: 0 - <high>Raw parameters</high> ddetermine the models <high>predictions</high> 1 - <high>Tuning parameters</high> determine the <high>estimation</high> of those raw parameters. <br> To determine <high>optimal tuning parameters</high>, which maximize prediction performance, techniques such as <high>cross validation</high> are often used. ] .pull-right4[ <br> <u>Example</u> |Model| Raw parameters|Tuning parameters| |:------|:------|:------| |Decision Trees|Nodes, splits, decisions |Minimum number of cases in each node| |Regularised regression |Model coefficients | Coefficient penalty term| ] --- # Optimizing model parameters with cross validation .pull-left5[ ### Cross validation procedure 0 - Select <high>tuning parameters</high><br> 1 - Split the training set into `K` <high>folds</high><br> 2 - Use `K-1` folds for training, and `1` fold for <high>testing</high>.<br> 3 - <high>Repeat</high> `K` times.<br> 4 - <high>Average</high> the `K` testing performances.<br> ] .pull-right45[ <br> <p align="center"> <img src="https://raw.githubusercontent.com/therbootcamp/Erfurt_2018June/master/_sessions/_image/crossvalidation.jpg" height="200px"></img> </p> ] --- # `caret` .pull-left55[ `caret` stands for <high>C</high>lassification <high>A</high>nd <high>RE</high>gression <high>T</high>raining. `caret` is a <high>wrapper package</high> that automates much of the the machine learning process. `caret` provides <high>hundreds of different ML algorithms</high> by changing <high>one `character` string</high> to use a different model. `caret` knows each model's <high>tuning parameters</high> and chooses the best ones for your data using cross validation (or other method). ```r library(caret) train(..., method = "lm") # Regression! train(..., method = "rf") # Random forests! train(..., method = "ada") # Boosted trees ``` ] .pull-right4[ <p align="center"> <br><br><br> <img src="https://3qeqpr26caki16dnhd19sv6by6v-wpengine.netdna-ssl.com/wp-content/uploads/2014/09/Caret-package-in-R.png"></img> <br>`caret` </p> ] --- # `caret` .pull-left55[ Here are the <high>main functions</high> we will cover from the `caret` package. | Function| Purpose| |--------|----------| | `createDataPartition()` | Split data into different partitions| | `trainControl()` | Determine how training (in general) will be done| | `train()` | Specify a model and find *best* parameters| | `varImp()` | Determine variable importance | | `predict()` | Predict values for new data| | `postResample()` | Evaluate prediction performance| ] .pull-right4[ The `caret` package has some of the *best* documentation (vignettes) you'll ever see... <p align="center"> <img src="caret_vignette.jpg" height="350px"> </p> ] --- # `createDataPartition` .pull-left6[ Use `createDataPartition()` to <high>split a dataset</high> into separate partitions, such as training and test data sets. ```r # Get training cases train_v <- createDataPartition(y = data$income, #crit times = 1, p = .5)$Resample1 # Vector of training cases train_v[1:10] ``` ``` ## [1] 3 4 6 8 10 11 12 15 17 18 ``` ```r # Training Data baselers_train <- data %>% slice(train_v) # Testing Data baselers_test <- data %>% slice(-train_v) ``` ] .pull-right35[ ```r # Testing data dim(baselers_train) ``` ``` ## [1] 3072 20 ``` ``` ## # A tibble: 4 x 3 ## id sex age ## <int> <chr> <dbl> ## 1 4 male 27 ## 2 6 male 63 ## 3 8 female 41 ## 4 10 female 31 ``` ```r # Training data baselers_train ``` ```r # Testing data dim(baselers_test) ``` ``` ## [1] 3068 20 ``` ] --- # `trainControl` .pull-left55[ Use `trainControl()` to define how `carat` should <high>select the best parameters</high> for a ML model. Here you can specify repeated <high>cross validation</high>. Many other methods are available via the `method` argument (see `?trainControl`) ```r # Define how caret should fit models ctrl <- trainControl(method = "repeatedcv", number = 10, # 10 folds repeats = 2) # Repeat 2 times ``` ] .pull-right4[ <u>`method`-argument options</u> |method|Description| |:----|:----| |`"repeatedcv"` | Repeated cross-validation| |`"LOOCV"`| Leave one out cross-validation| |`"none"` | Fit one model with default parameters | ] --- # `train` .pull-left6[ Use `train()` to <high>fit</high> 280+ models using <high>optimal parameters</high>. ```r rpart_train <- train(form = income ~ ., data = baselers_train, method = "rpart", # Model! trControl = ctrl) ``` <p align="center"><u>train()-function arguments</u></p> |Argument|Description| |:-----|:----| |`form`|Formula specifying criterion| |`data`|Training data| |`method`| Model| |`trControl`| Control parameters| ] .pull-right35[ Find all 280+ models [here](http://topepo.github.io/caret/available-models.html) <p align="center"> <img src="caret_models.jpg" height="350px"> </p> ] --- # `train` .pull-left6[ <high>Classification tasks</high> require the <high>criterion to be factor</high>, while regression tasks require it to be numeric. ```r # Will be a regression model reg_mod <- train(form = diagnosis ~ ., data = heartdisease, method = "rpart") ``` <font color='red' size = 3>Warning messages:...Are you sure you wanted to do regression?</font> Use `factor()` to <high>convert your criterion</high> to a factor, now you are doing classification! ```r # Use factor() to specify a classification model class_mod <- train(form = factor(diagnosis) ~ ., data = heartdisease, method = "rpart") ``` ] .pull-right35[ Find all 280+ models [here](http://topepo.github.io/caret/available-models.html) <p align="center"> <img src="caret_models.jpg" height="350px"> </p> ] --- # `train` ```r rpart_train ``` ``` ## CART ## ## 3072 samples ## 19 predictor ## ## No pre-processing ## Resampling: Cross-Validated (10 fold, repeated 2 times) ## Summary of sample sizes: 2764, 2764, 2765, 2766, 2765, 2765, ... ## Resampling results across tuning parameters: ## ## cp RMSE Rsquared MAE ## 0.06978 1461 0.7113 1177 ## 0.10853 1814 0.5549 1447 ## 0.54480 2211 0.5241 1782 ## ## RMSE was used to select the optimal model using the smallest value. ## The final value used for the model was cp = 0.06978. ``` --- # Explore the `train` object .pull-left4[ ```r # Best tuning parameters rpart_train$bestTune ``` ``` ## cp ## 1 0.06978 ``` ```r # Show the final model rpart_train$finalModel ``` ``` ## n= 3072 ## ## node), split, n, deviance, yval ## * denotes terminal node ## ## 1) root 3072 2.271e+10 7522 ## 2) age< 46.5 1826 5.051e+09 5864 * ## 3) age>=46.5 1246 5.289e+09 9952 ## 6) age< 66.5 919 1.975e+09 9113 * ## 7) age>=66.5 327 8.484e+08 12310 * ``` ] .pull-right55[ ```r # Plot final model plot(rpart_train$finalModel) text(rpart_train$finalModel) ``` <img src="MachineLearningII_files/figure-html/unnamed-chunk-20-1.png" style="display: block; margin: auto;" /> ] --- .pull-left5[ # `varImp` Use `varImp()` to extract <high>variable importance</high> from a model, i.e., how (relatively) important each variable was in predicting the criterion. ```r # Plot variable importance plot(varImp(rpart_train)) ``` 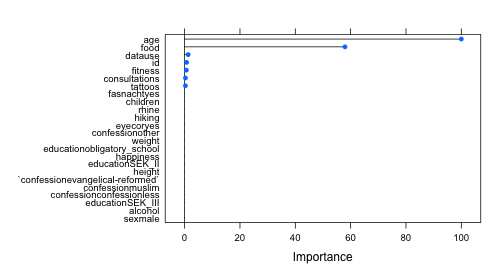<!-- --> ] .pull-right45[ ```r # Get veriable importance from rpart_train varImp(rpart_train) ``` ``` ## rpart variable importance ## ## only 20 most important variables shown (out of 24) ## ## Overall ## age 100.000 ## food 57.957 ## datause 1.256 ## id 0.728 ## fitness 0.626 ## consultations 0.284 ## tattoos 0.283 ## fasnachtyes 0.000 ## sexmale 0.000 ## educationobligatory_school 0.000 ## alcohol 0.000 ## rhine 0.000 ## educationSEK_II 0.000 ## educationSEK_III 0.000 ## weight 0.000 ## children 0.000 ## confessionother 0.000 ## confessionmuslim 0.000 ## eyecoryes 0.000 ## hiking 0.000 ``` ] --- # `predict`, `postResample` .pull-left5[ Assess prediction performance with <high>`predict()`</high>, summarise performance with <high>`postResample()`</high>. ```r # Get predictions based on best bas_pred <- predict(object = rpart_train, newdata = baselers_test) # Result is a vector of predictions # for each row in newdata bas_pred[1:5] ``` ``` ## 1 2 3 4 5 ## 5864 9113 12310 5864 5864 ``` ```r # Assess performance with postResample() postResample(pred = bas_pred, obs = baselers_test$income) ``` ``` ## RMSE Rsquared MAE ## 1560.3574 0.6752 1261.1642 ``` ] .pull-right45[ ```r # Plot predictions versus truth tibble(pred = bas_pred, obs = baselers_test$income) %>% ggplot(aes(x = pred, y = obs)) + geom_point(alpha = .1) + labs(title = "Rpart Performance", x = "Predictions", y = 'Truth') + theme_bw() + geom_smooth(method = "lm") ``` <img src="MachineLearningII_files/figure-html/unnamed-chunk-24-1.png" style="display: block; margin: auto;" /> ] --- .pull-left5[ # ML steps with caret Step 0: Create training and test data (if necessary) ```r train_v <- createDataPartition(y, times, p) data_train <- data %>% slice(train_v) data_test <- data %>% slice(-train_v) ``` Step 1: Define control parameters ```r ctl <- trainControl(method = "repeatedcv", number = 10, repeats = 2) ``` Step 2: Train model ```r rpart_train <- train(form = income ~ ., data = data_train, method = "rpart", trControl = ctl) ``` ] .pull-right45[ <br><br><br><br><br> Step 3: Explore ```r rpart_train # Print object varImp(rpart_train) # Var importance rpart_train$finalModel # Final model ``` Step 4: Predict ```r my_pred <- predict(object = rpart_train, newdata = data_test) ``` Step 5: Evaluate ```r postResample(pred = bas_pred, obs = baselers_test$income) ``` ] --- # Practical <font size=6><b><a href="https://therbootcamp.github.io/BaselRBootcamp_2018July/_sessions/MachineLearningII/MachineLearningII_practical.html">Link to practical</a>