Plotting II
|
Explorative Datenanalyse mit R The R Bootcamp |

|

adapted from paherald.sk.ca
Überblick
In diesem Practical wirst du weiter üben mit ggplot2 schöne Grafiken zu erstellen.
Am Ende des Practicals wirst du wissen wie man:
facets benutzt.themes undscales anpasst.- Bilddateien erstellt.
- Multiple Plots verbindet.
Aufgaben
A - Setup
Öffne dein
TheRBootcampR project. Es sollte die Ordner1_Dataund2_Codeenthalten.Öffne ein neues R Skript. Schreibe deinen Namen, das Datum und “PlottingII Practical” als Kommentare an den Anfang des Skripts.
## NAME
## DATUM
## PlottingII PracticalSpeichere das neue Skript unter dem Namen
plottingII_practical.Rim2_CodeOrdner.Lade
tidyverse,viridis, undpatchwork.
B - Lade den Datensatz
Verwende die
read_csv()Funktion um den Datensatzverbrechen.csvals Objektverbrecheneinzulesen. Denke an den Trick mit den Anführungszeichen.Printe den Datensatz. Wurden alle Variablentypen korrekt identifiziert?
Verwende
summary()um einen weiteren Überblick über die Daten zu bekommen.
C - facets
In diesem Abschnitt analysierst du den Zusammenhang zwischen dem Anteil der Bevölkerung, die mit der Metro fahren, und der Häufigkeit verschiedener Verbrechen.
- Verwende den folgenden Code um die Beziehung zwischen
prozent_metro(x-Achse) undhaeufigkeit(y-Achse) zu plotten.
ggplot(XX, aes(x = XX,
y = XX)) +
geom_point(alpha = .3) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
theme_minimal()ggplot(verbrechen, aes(x = prozent_metro,
y = haeufigkeit)) +
geom_point(alpha = .3) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
theme_minimal()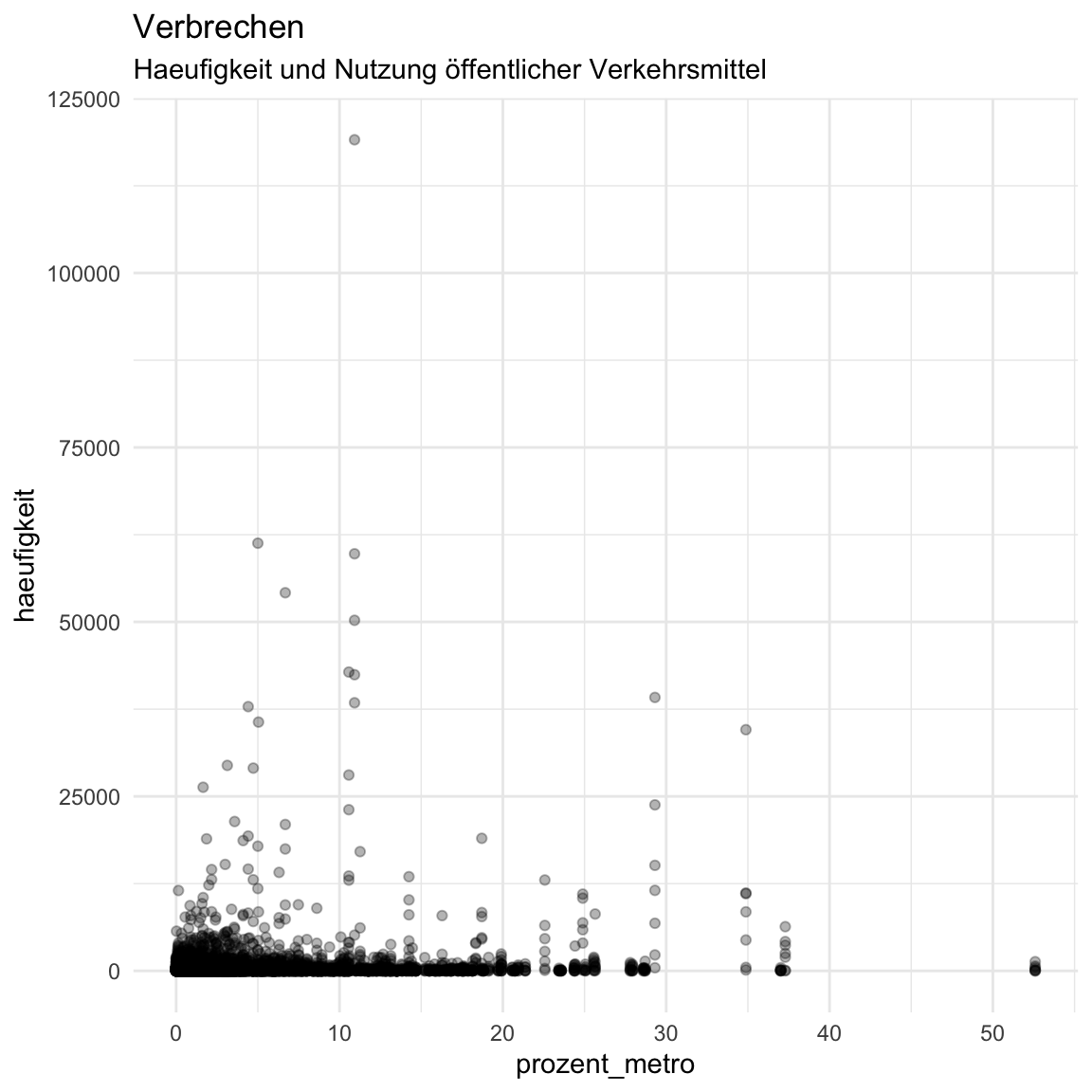
- Sieht noch nicht so informativ aus. Ergänze
scale_x_continuous(trans = 'pseudo_log')undscale_y_continuous(trans = 'pseudo_log')um die y und x-Achse zu stauchen. Später noch mehr zu Skalierungen.
ggplot(verbrechen, aes(x = prozent_metro,
y = haeufigkeit)) +
geom_point(alpha = .3) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log')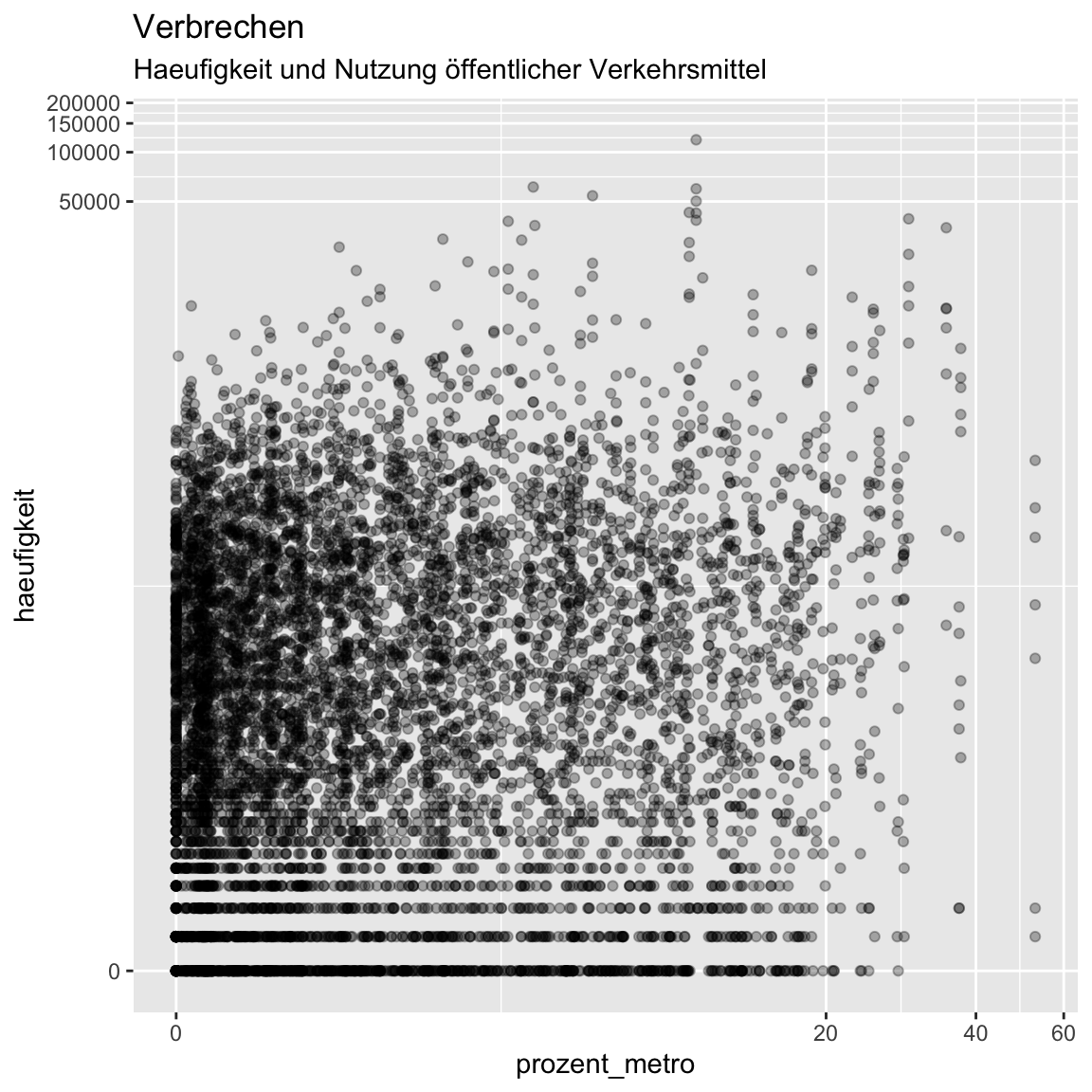
- Besser, oder? Jetzt zeichnet sich ein schwach positiver Zusammenhang ab. Könnte das anders aussehen, wenn man die verschiedenen Klassen von Verbrechen differenziert? Versuche dies mal mit der Verwendung verschiedener Farben indem du
verbrechendemcolArgument inaes()zuweist.
ggplot(verbrechen, aes(x = prozent_metro,
y = haeufigkeit,
col = verbrechen)) +
geom_point(alpha = .3) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log')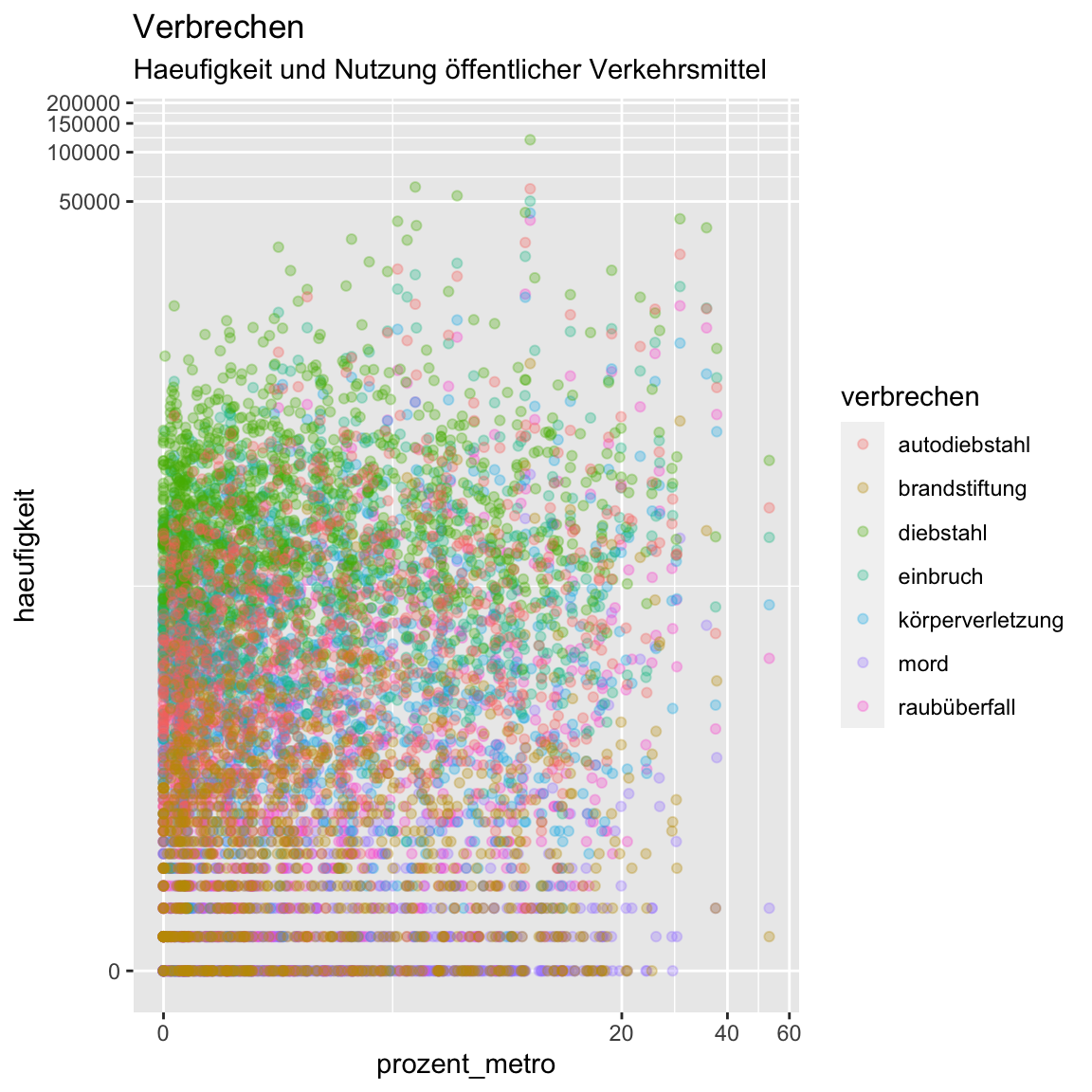
- Wieder nicht wirklich informativ, oder? Anstatt mit
colversuche nun die verschiedenen Verbrechen mitfacet_wrap()zu differenzieren. Siehe unten.
ggplot(XX, aes(x = XX,
y = XX)) +
geom_point(alpha = .3) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log') +
facet_wrap(~ XX)ggplot(verbrechen, aes(x = prozent_metro,
y = haeufigkeit)) +
geom_point(alpha = .2) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log') +
facet_wrap(~verbrechen)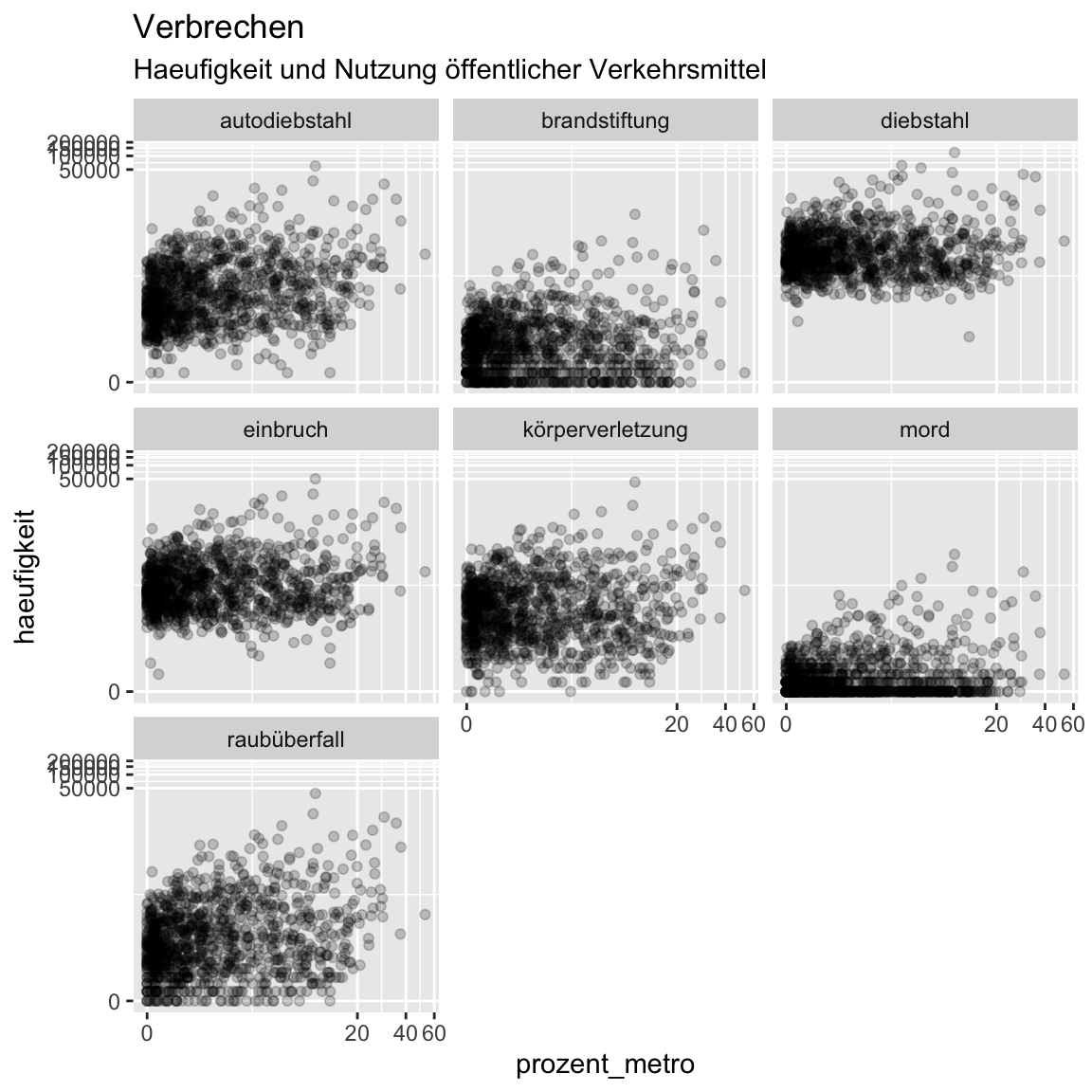
- Es zeichnet sich ab, dass nicht alle Verbrechen gleich mit dem Anteil Metro-Fahrender zusammenhängen. Der stärkste Zusammenhang scheint zu Autodiebstählen und Raubüberfällen zu bestehen. Kann aber natürlich sein, dass eine dritte Variable diesen Zusammenhang treibt, z.B. der Prozentsatz unter der Armutsgrenze lebender Personen. Verwende
facet_grid()um gleichzeitig nach Verbrechen undprozent_armutkleiner oder grösser 10% zu differenzieren. Wie du im Code siehst, kannst du den logischen Vergleich direkt in die Funktion schreiben.
ggplot(XX, aes(x = XX,
y = XX)) +
geom_point(alpha = .3) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log') +
facet_grid(XX > 10 ~ XX)ggplot(verbrechen, aes(x = prozent_metro,
y = haeufigkeit)) +
geom_point(alpha = .2) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log') +
facet_grid(prozent_armut > 10 ~ verbrechen)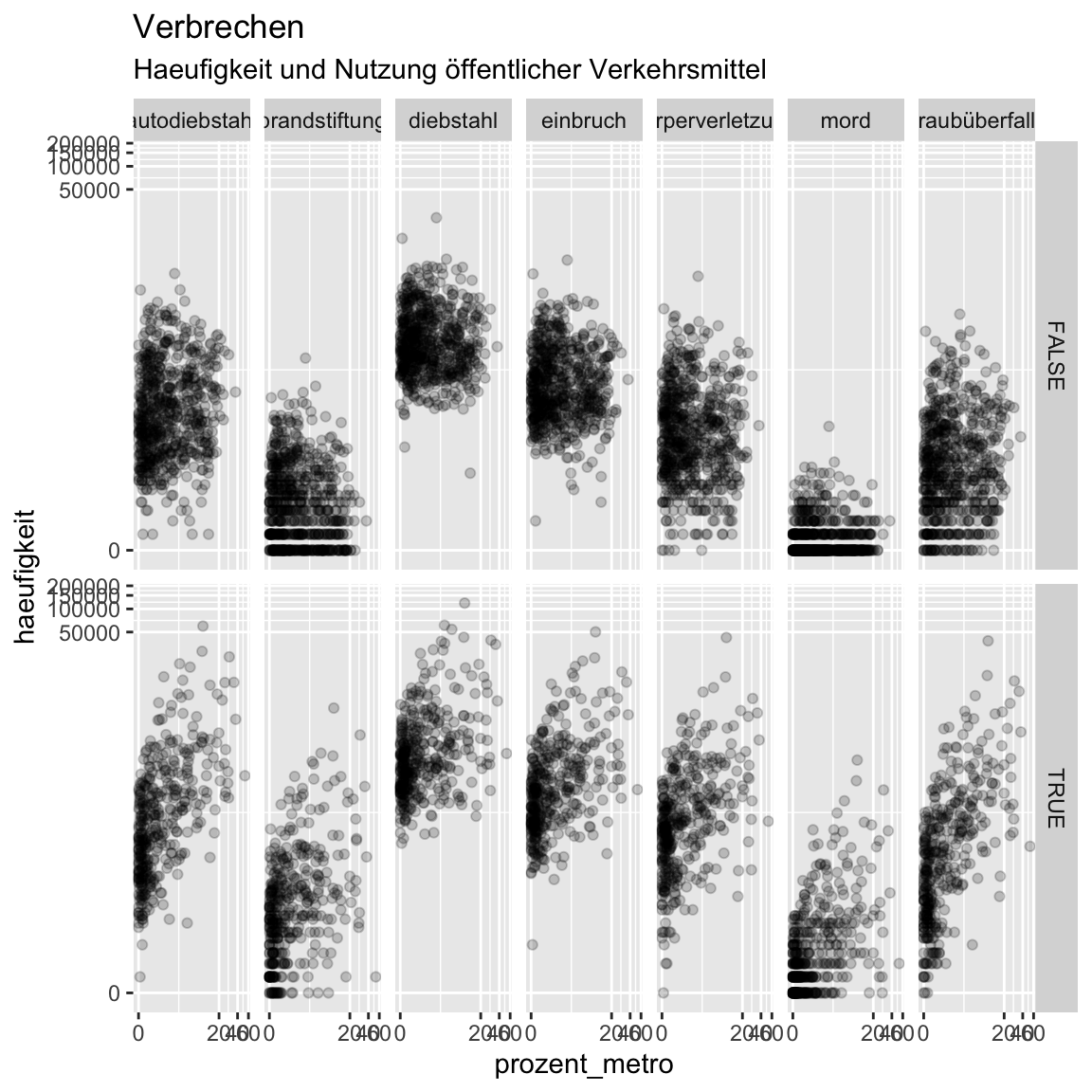
- Relativ eindeutig: Die Anzahl Metro-fahrender ist nur mit Verbrechen assoziiert, wenn die Bezirke eine hohe Armut aufweisen. Gleichzeitig gibt es praktisch keine Differenzierung mehr: Alle Verbrechen sind mit der Anzahl Metro-fahrender assoziert. Seltsam, oder? Vielleicht haben wir noch nicht die richtige Drittvariable. Probiere doch mal
bevoelkerung_dichtegrösser als5000als erste Variable infacet_grid()aus.
ggplot(XX, aes(x = XX,
y = XX)) +
geom_point(alpha = .3) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log') +
facet_grid(XX > 5000 ~ XX)ggplot(verbrechen, aes(x = prozent_metro,
y = haeufigkeit)) +
geom_point(alpha = .2) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log') +
facet_grid(bevoelkerung_dichte > 5000 ~ verbrechen)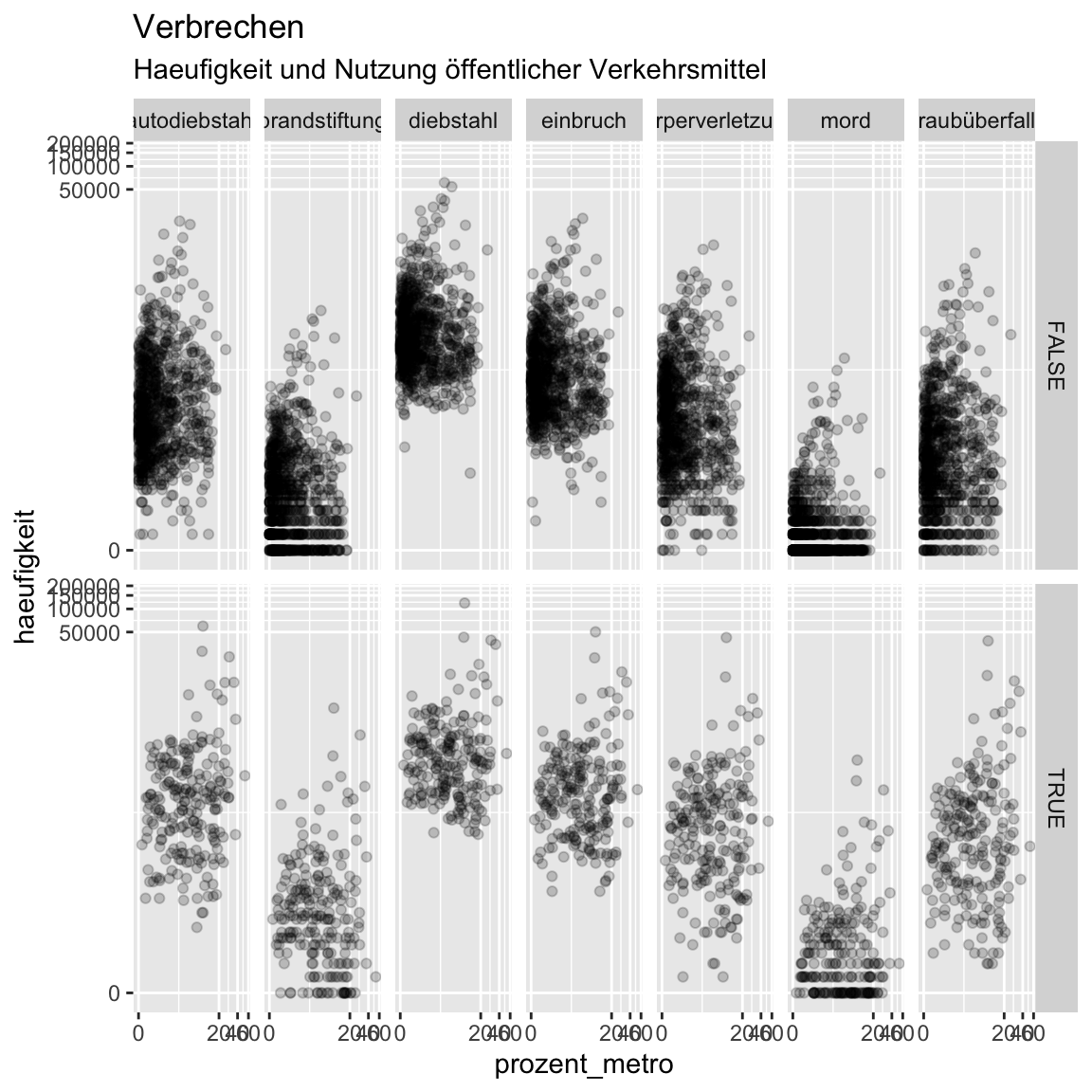
- Der Zusammenhang ist verschwunden. Wir haben von Beginn an übersehen, dass viele Metro-fahrer stark mit einer hohen Bevölkerungsdichte assoziert ist und diese wiederum mit der Anzahl von Delikten. Wenn du magst, exploriere die Daten ein wenig weiter. Welche Zusammenhänge kannst du noch entdecken?
D - themes
In diesem Abschnitt passt du deinen Lieblingsplot aus dem letzten Abschnitt mit der theme() Funktion an.
- Zuallererst speichere einen deiner Plots aus dem letzten Abschnitt als ein
ggObjekt mit Namenverbrechen_gg.
verbrechen_gg <- XXverbrechen_gg <- ggplot(verbrechen,
aes(x = prozent_metro,
y = haeufigkeit)) +
geom_point(alpha = .2) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log') +
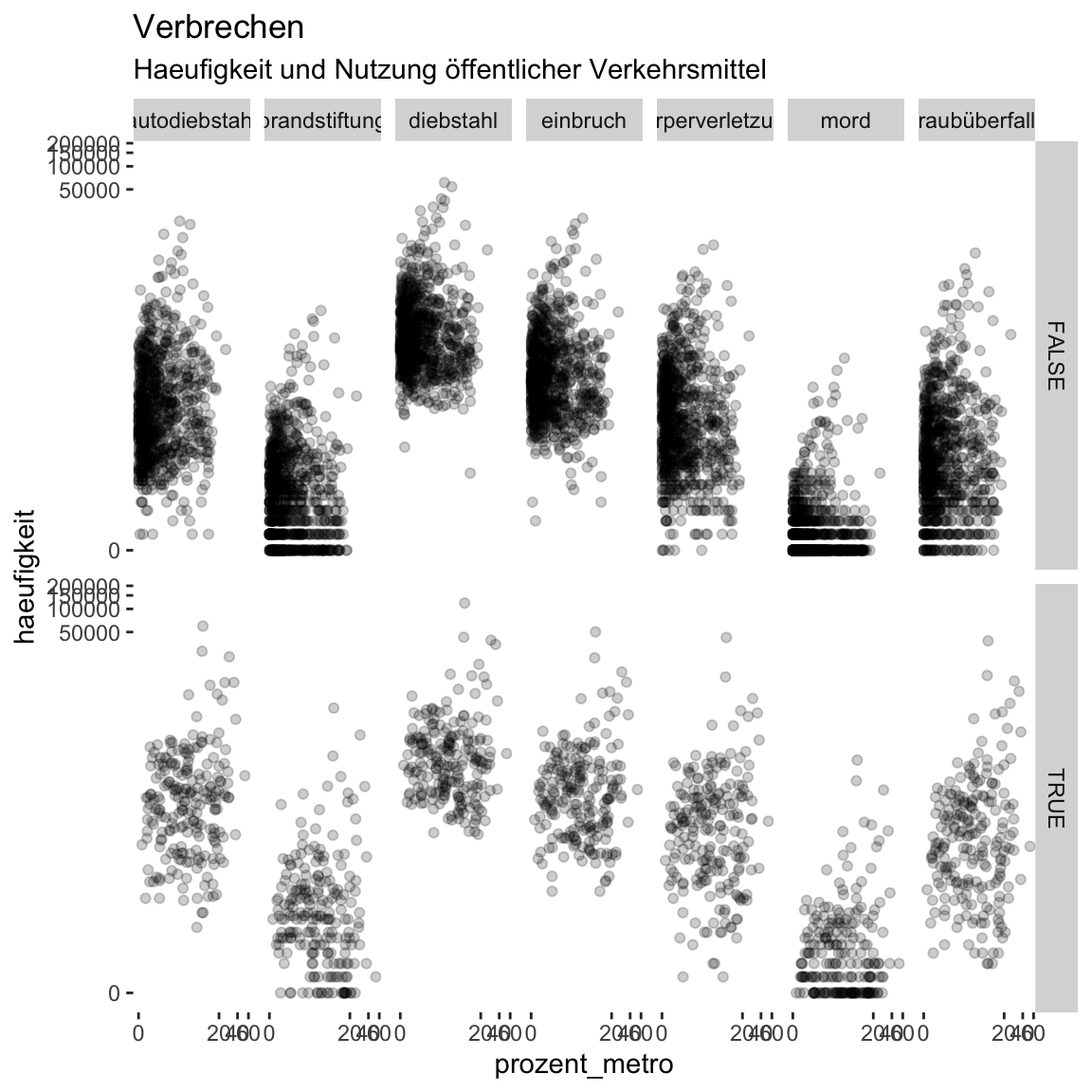
facet_grid(bevoelkerung_dichte > 5000 ~ verbrechen)- Ändere die Farbe des Hintergrunds des Panels zu
"white". Verwende hierzu daspanel.backgroundin dertheme()Funktion und dieelement_rect()Helferfunktion.
verbrechen_gg +
theme(
panel.background = element_rect(fill = XX)
)verbrechen_gg +
theme(
panel.background = element_rect(fill = 'white')
)
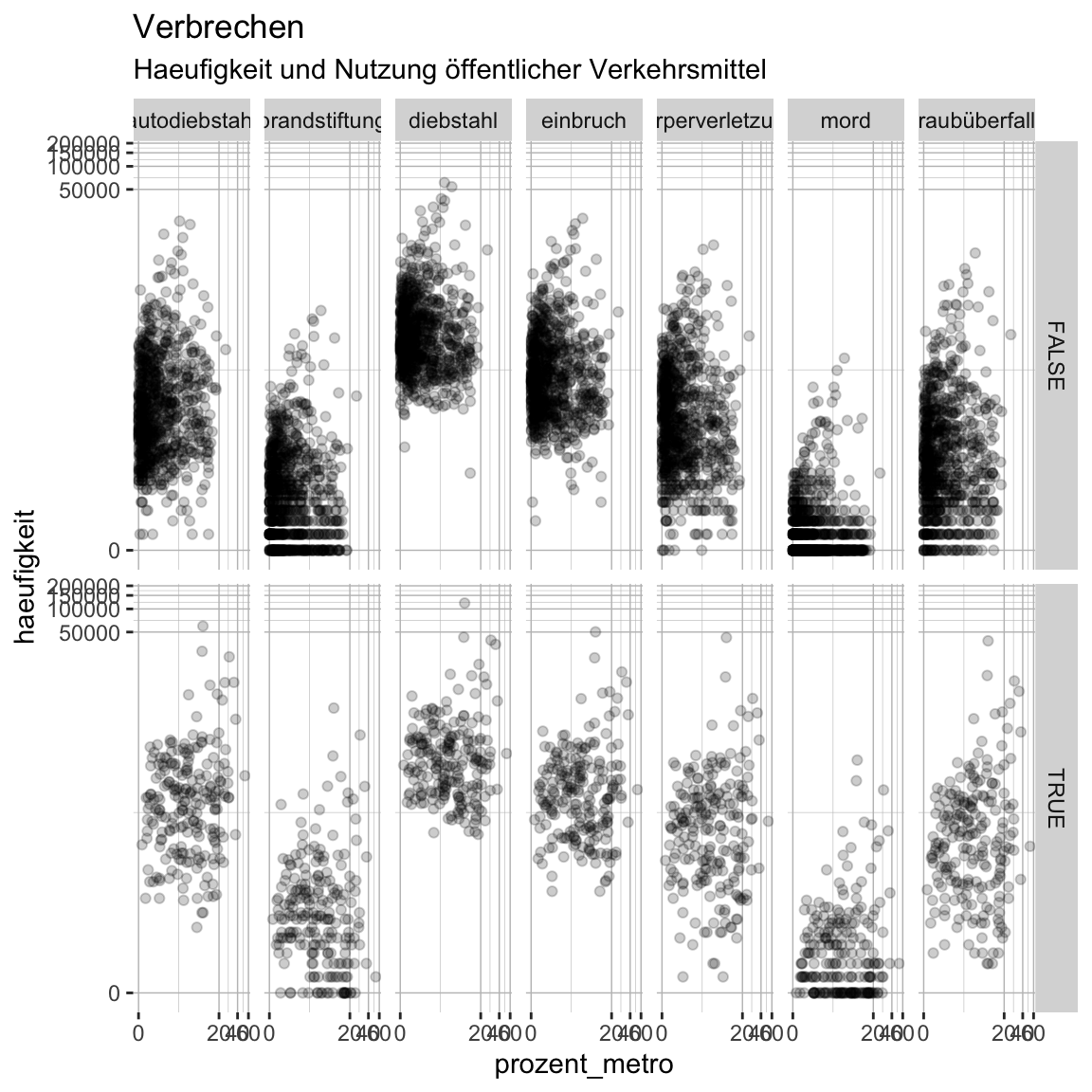
- Als nächstes, ändere die Farbe der Haupt- und Nebenlinien zu
"grey75"und deren Grössen zu.25und.1respektive. Verwende hierzu die Argumentepanel.grid.majorundpanel.grid.minorund die Helferfunktionelement_line().
verbrechen_gg +
theme(
panel.background = element_rect(fill = XX),
panel.grid.major = element_line(color = XX, size = XX),
panel.grid.minor = element_line(color = XX, size = XX)
)verbrechen_gg +
theme(
panel.background = element_rect(fill = 'white'),
panel.grid.major = element_line(color = 'grey75', size = .25),
panel.grid.minor = element_line(color = 'grey75', size = .1)
)
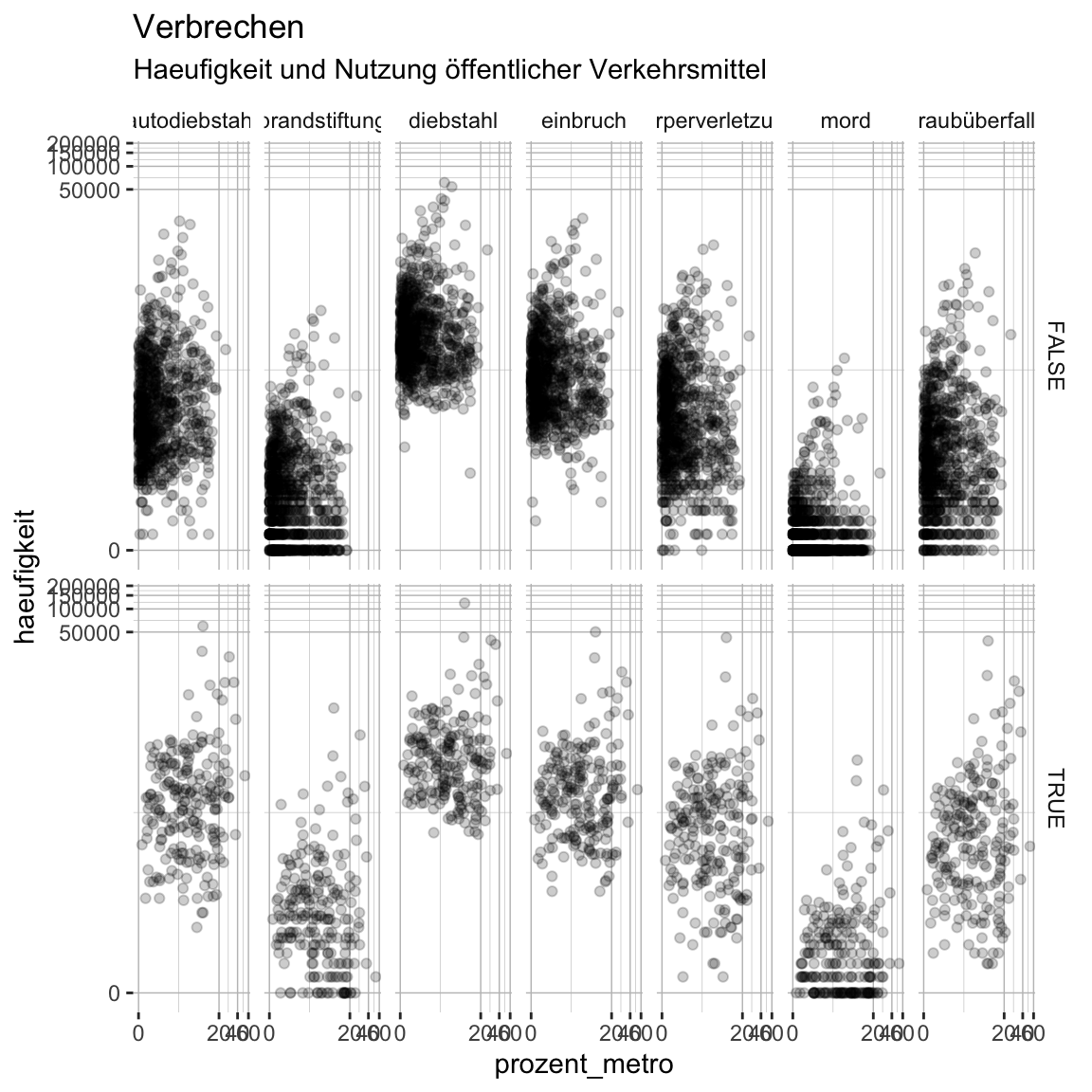
- Ändere nun die Farbe des Hintergunds der Panel-Überschriften zu
white. Verwende dasstrip.backgroundArgument und wiederum dieelement_rect()Helferfunktion.
verbrechen_gg +
theme(
panel.background = element_rect(fill = XX),
panel.grid.major = element_line(color = XX, size = XX),
panel.grid.minor = element_line(color = XX, size = XX),
strip.background = element_rect(fill = XX),
)verbrechen_gg +
theme(
panel.background = element_rect(fill = 'white'),
panel.grid.major = element_line(color = 'grey75', size = .25),
panel.grid.minor = element_line(color = 'grey75', size = .1),
strip.background = element_rect(fill = 'white')
)
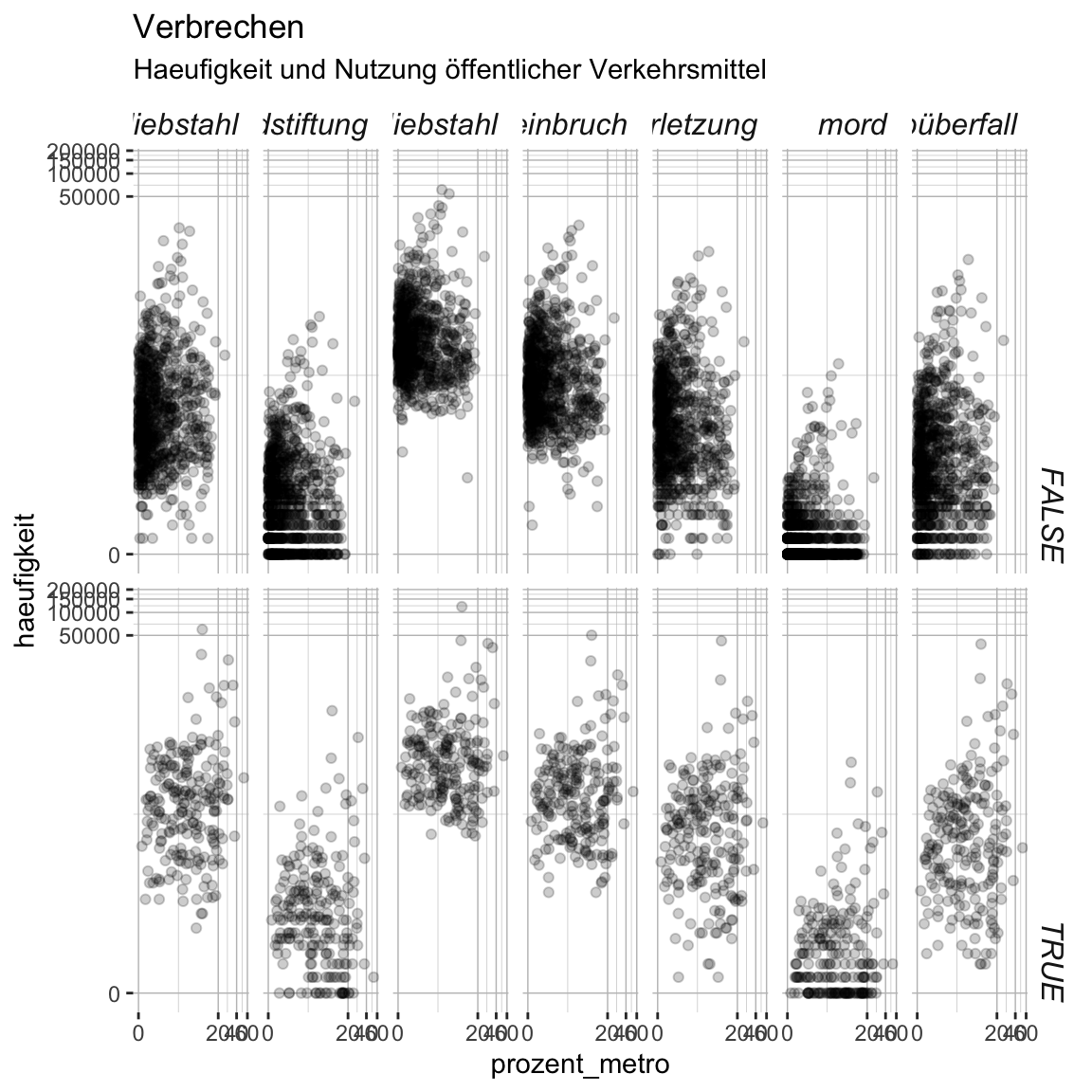
- Nun ändere die Schriftart der Überschriften zu
italicmit demfaceArgument, setze den Text rechtsbündig (hjust = 1) und die Schriftgrösse (size) auf12. Verwende hierzu dasstrip.textArgument und die genannten Argumente inelement_text(). Siehe?element_text().
verbrechen_gg +
theme(
panel.background = element_rect(fill = XX),
panel.grid.major = element_line(color = XX, size = XX),
panel.grid.minor = element_line(color = XX, size = XX),
strip.background = element_rect(fill = XX),
strip.text = element_text(face = XX, size = XX, hjust = XX)
)verbrechen_gg +
theme(
panel.background = element_rect(fill = 'white'),
panel.grid.major = element_line(color = 'grey75', size = .25),
panel.grid.minor = element_line(color = 'grey75', size = .1),
strip.background = element_rect(fill = 'white'),
strip.text = element_text(face = 'italic', size = 12, hjust = 1)
)
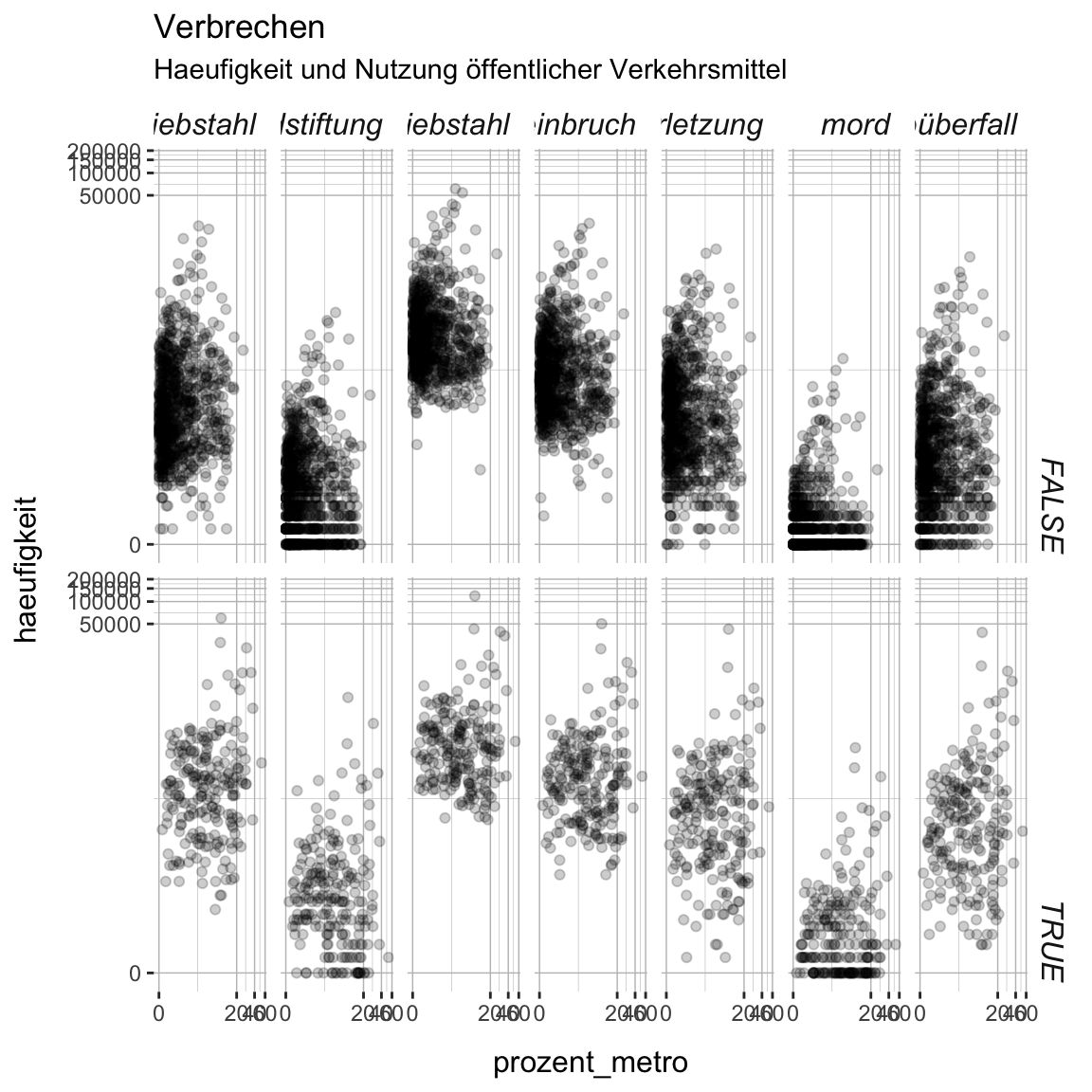
- Setze noch die Schriftgrösse der Achsenbeschriftungen auf
12und setze jeweils einen Abstand von10. Verwende hierzu die Argumenteaxis.title.xundaxis.title.yund die Helferfunktionenelement_text()undmargin(). Siehe?margin().
verbrechen_gg +
theme(
panel.background = element_rect(fill = XX),
panel.grid.major = element_line(color = XX, size = XX),
panel.grid.minor = element_line(color = XX, size = XX),
strip.background = element_rect(fill = XX),
strip.text = element_text(face = XX, size = XX, hjust = XX),
axis.title.x = element_text(size = XX, margin = margin(t = XX)),
axis.title.y = element_text(size = XX, margin = margin(r = XX)),
)verbrechen_gg +
theme(
panel.background = element_rect(fill = 'white'),
panel.grid.major = element_line(color = 'grey75', size = .25),
panel.grid.minor = element_line(color = 'grey75', size = .1),
strip.background = element_rect(fill = 'white'),
strip.text = element_text(face = 'italic', size = 12, hjust = 1),
axis.title.x = element_text(size = 12, margin = margin(t = 10)),
axis.title.y = element_text(size = 12, margin = margin(r = 10))
)
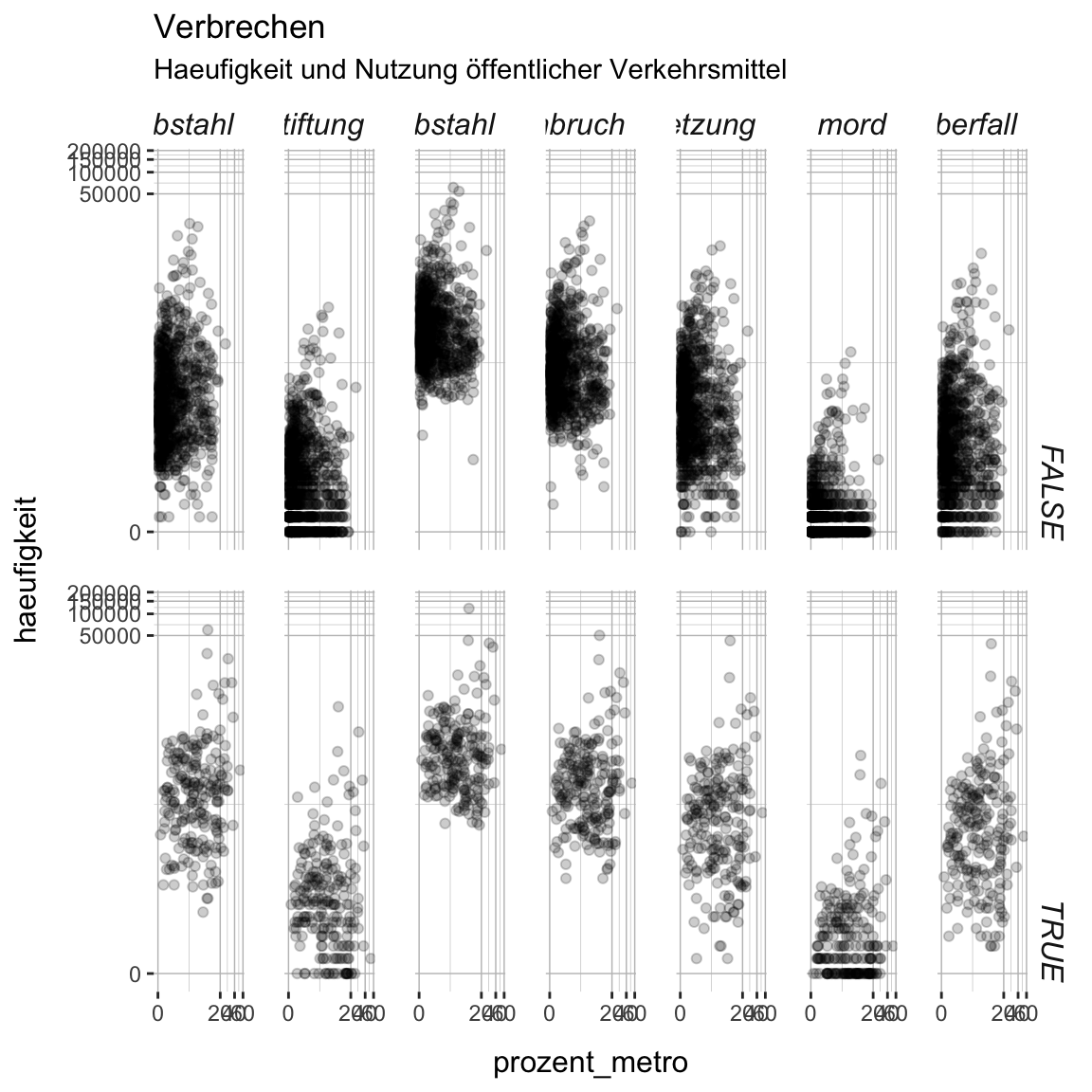
- Abschliessend erhöhe den Abstand zwischen den Panels auf
1.1in der Einheit"lines"mittels despanel.spacingArgument und derunit()Funktion.
verbrechen_gg +
theme(
panel.background = element_rect(fill = XX),
panel.grid.major = element_line(color = XX, size = XX),
panel.grid.minor = element_line(color = XX, size = XX),
strip.background = element_rect(fill = XX),
strip.text = element_text(face = XX, size = XX, hjust = XX),
axis.title.x = element_text(size = XX, margin = margin(t = XX)),
axis.title.y = element_text(size = XX, margin = margin(r = XX)),
panel.spacing = unit(XX, units = XX)
)verbrechen_gg +
theme(
panel.background = element_rect(fill = 'white'),
panel.grid.major = element_line(color = 'grey75', size = .25),
panel.grid.minor = element_line(color = 'grey75', size = .1),
strip.background = element_rect(fill = 'white'),
strip.text = element_text(face = 'italic', size = 12, hjust = 1),
axis.title.x = element_text(size = 12, margin = margin(t = 10)),
axis.title.y = element_text(size = 12, margin = margin(r = 10)),
panel.spacing = unit(1.1, units = "lines")
)
E - Mein theme() Objekt
- Speichere nun alle bisher genutzten
themeEinstellungen in ein eigenes Objekt mit dem Namenmein_theme.
mein_theme <- theme(
XX = XX,
XX = XX,
...
)mein_theme <- theme(
panel.background = element_rect(fill = 'white'),
panel.grid.major = element_line(color = 'grey75', size = .25),
panel.grid.minor = element_line(color = 'grey75', size = .1),
strip.background = element_rect(fill = 'white'),
strip.text = element_text(face = 'italic', size = 12, hjust = 1),
axis.title.x = element_text(size = 12, margin = margin(t = 10)),
axis.title.y = element_text(size = 12, margin = margin(r = 10)),
panel.spacing = unit(1.1, units = "lines")
)- Jetzt kreiere einen neuen Plot mit anderen Variablen als zuvor und ergänze
mein_theme(Ohne Klammern).
ggplot(verbrechen,
aes(x = XX,
y = XX)) +
geom_point() +
facet_wrap(~ XX) +
mein_themeggplot(verbrechen,
aes(x = median_einkommen,
y = haeufigkeit)) +
geom_point() +
facet_wrap(~ staat) +
mein_theme- Wenn dir
mein_themenicht gefällt, geh zur 1. Aufgabe und nimmm Änderungen vor. Siehe?theme. Probiere zum Beispiel mal die Argumenteaxis.ticksundstrip.placementaus.
F - Skalierung
In diesem Abschnitt passt du die Skalierung von Achsen und Objekten an.
- Bevor du anfängst Skalierungen anzupassen, spezifizere zwei weitere Elemente von
aes(), so damit es später mehr zu skalieren gibt. Weise im Code untenstaatdem Argumentcolzu undbevoelkerungdem Argumentsize. Speichere den Plot wiederum alsverbrechen_ggund plotte den Plot einmal.
verbrechen_gg <- ggplot(data = verbrechen,
mapping = aes(x = prozent_metro,
y = haeufigkeit,
col = XX,
size = XX)) +
geom_point(alpha = .5) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log') +
facet_wrap(~ verbrechen) +
mein_theme
verbrechen_ggverbrechen_gg <- ggplot(data = verbrechen,
mapping = aes(x = prozent_metro,
y = haeufigkeit,
col = staat,
size = bevoelkerung)) +
geom_point(alpha = .5) +
labs(title = "Verbrechen",
subtitle = "Haeufigkeit und Nutzung öffentlicher Verkehrsmittel") +
scale_x_continuous(trans = 'pseudo_log') +
scale_y_continuous(trans = 'pseudo_log') +
facet_wrap(~ verbrechen) +
mein_theme
verbrechen_gg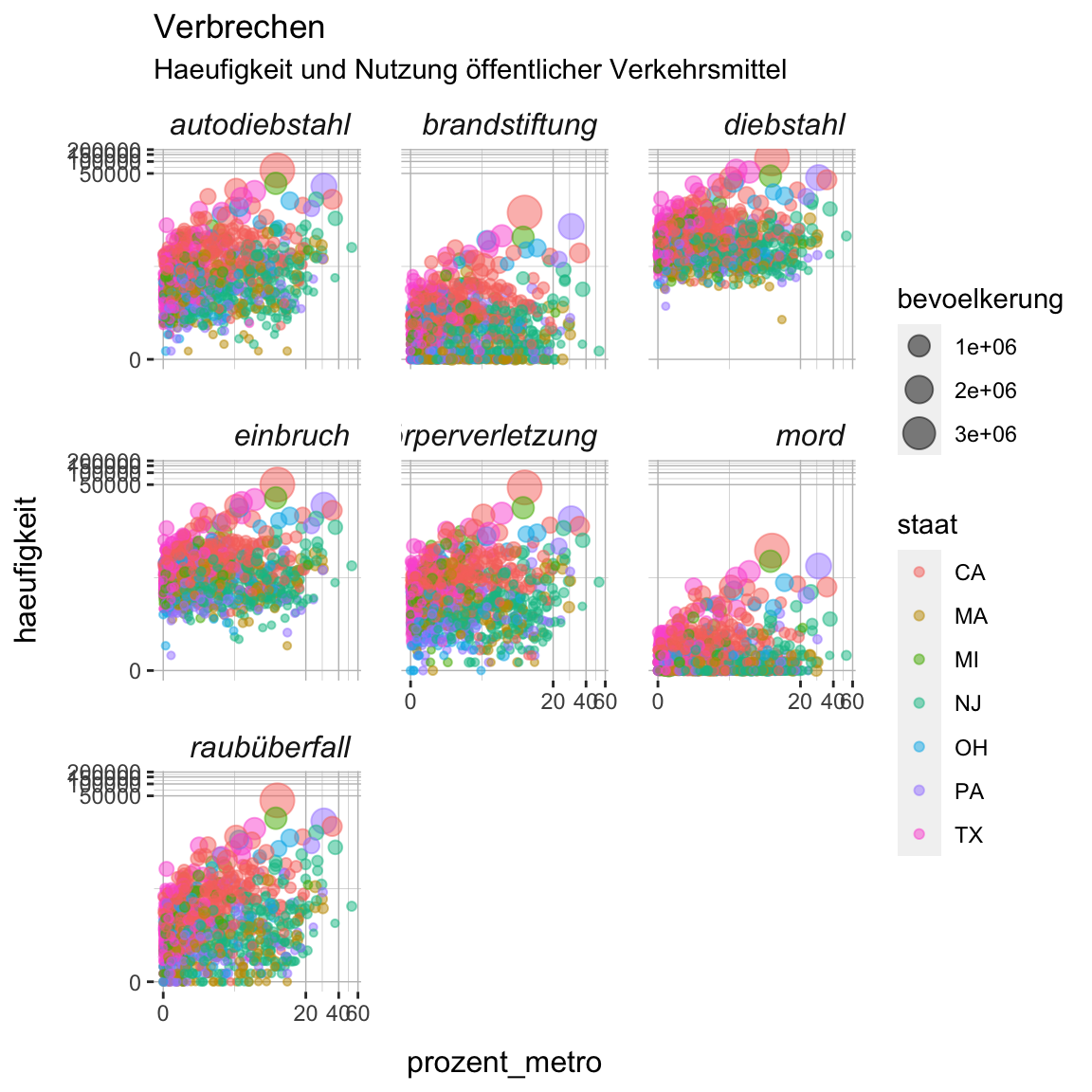
- Als erstes verwende
scale_size()und darin dasrangeargument um die Grösse der Punkte zu verkleinern. Damit kannst du die Überlappung etwas verringern. Probiere ein paar Werte für die untere und obere Grenze aus, die jeweils kleiner als10sein sollten, um einen guten Trade-off zwischen Grösse und Überlappung zu finden.
verbrechen_gg + scale_size(range = c(XX, XX))verbrechen_gg + scale_size(range = c(.5, 3))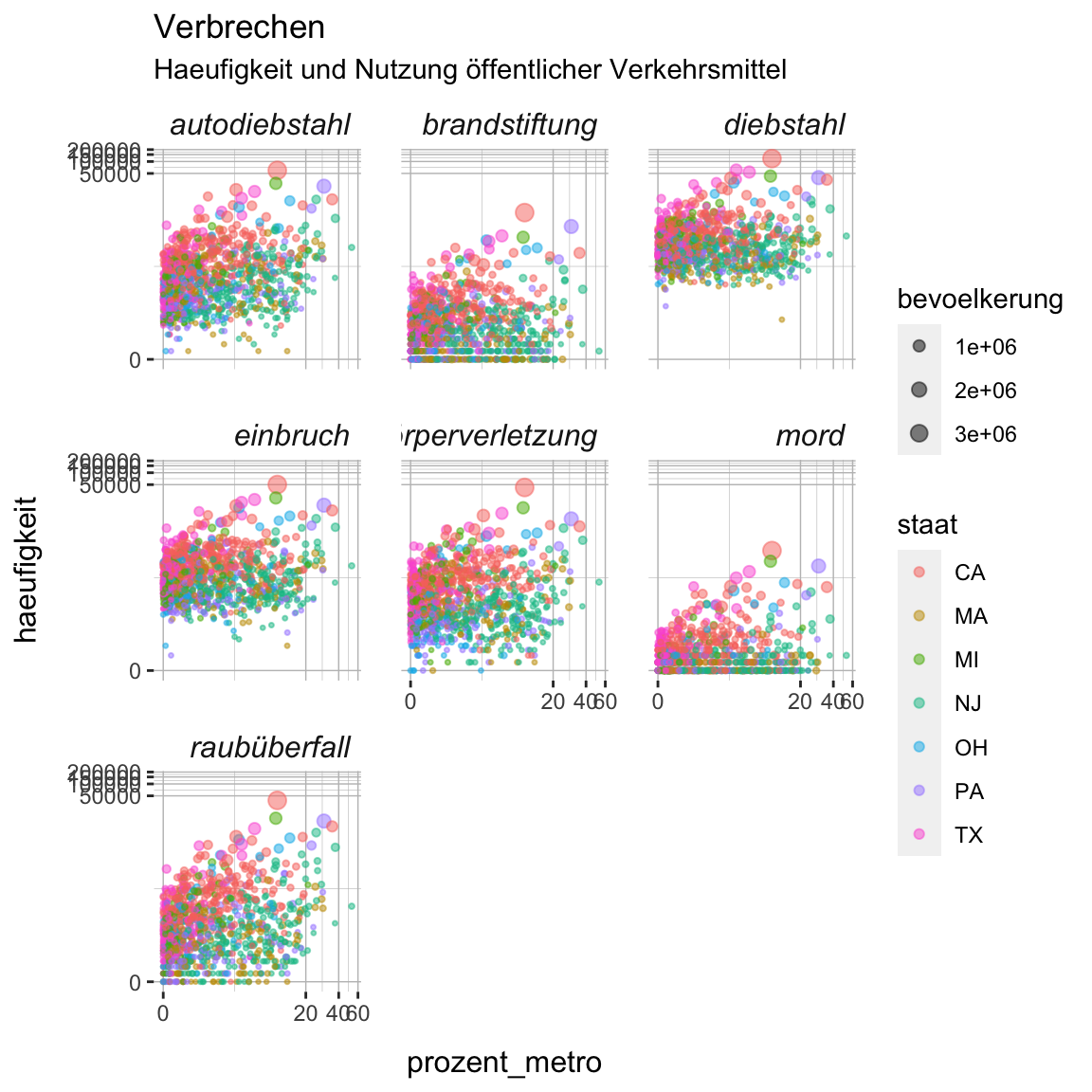
- Nun ändere die Farben mit
scale_color_colorblind()(spezifische Version vonscale_color_gradient()), so dass die Farben auch hinsichtlich Helligkeit voneinander abgrenzbar sind.
verbrechen_gg +
scale_size(range = c(XX, XX)) +
scale_color_colorblind()verbrechen_gg +
scale_size(range = c(.5, 3)) +
scale_color_colorblind()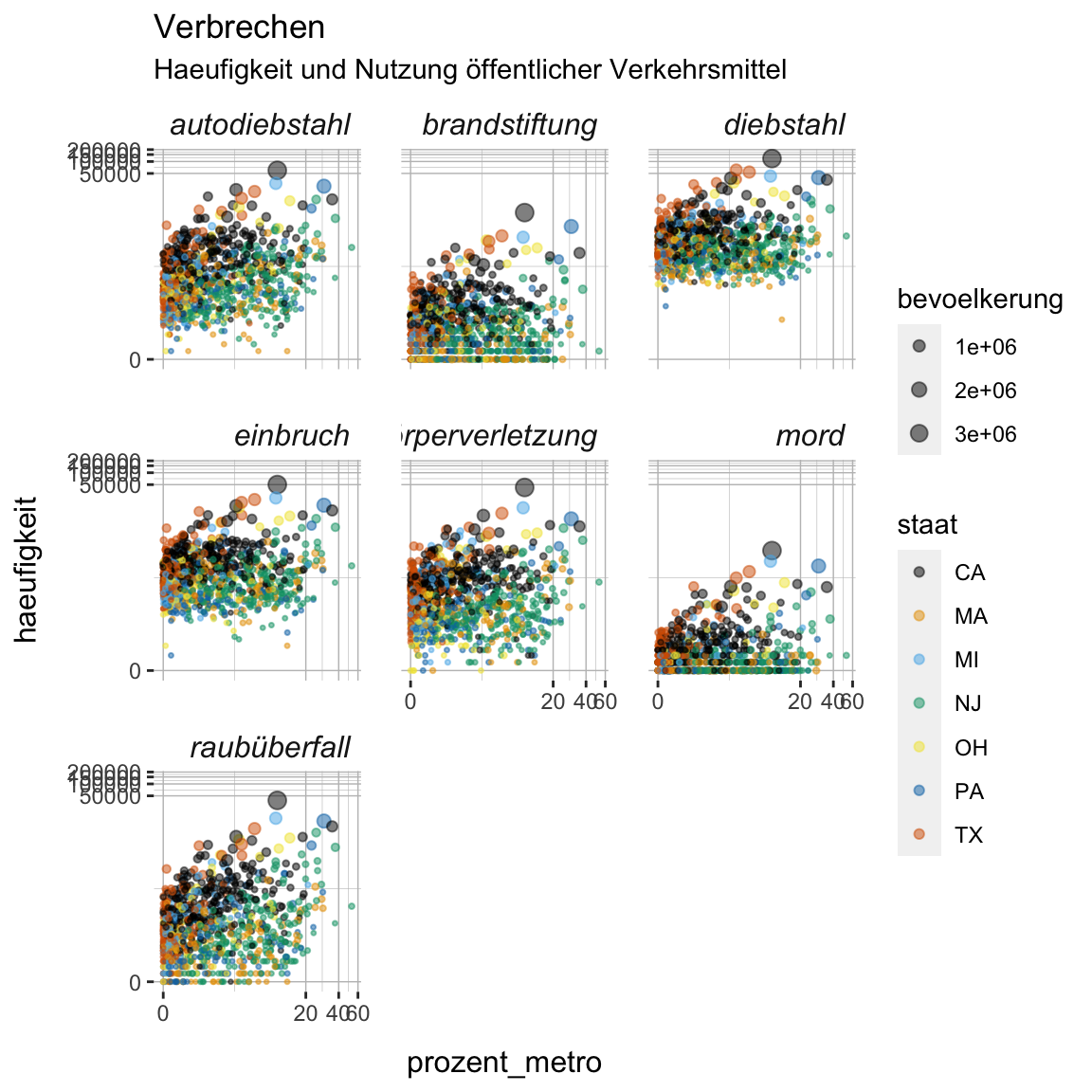
- Alternativ kann man die Farbskala selbst setzen. Verwende
scale_color_manual()und dieviridis()Funktion aus demviridisPaket (nicht vergessen zu laden) um die Farben manuell anzupassen. Viridis ist ein anderer, etablierter und schönerer Farbsatz, der ebenfalls Helligkeitsunterschiede berücksichtigt.
verbrechen_gg +
scale_size(range = c(XX, XX)) +
scale_color_manual(values = viridis(7))verbrechen_gg +
scale_size(range = c(.5, 3)) +
scale_color_manual(values = viridis(7))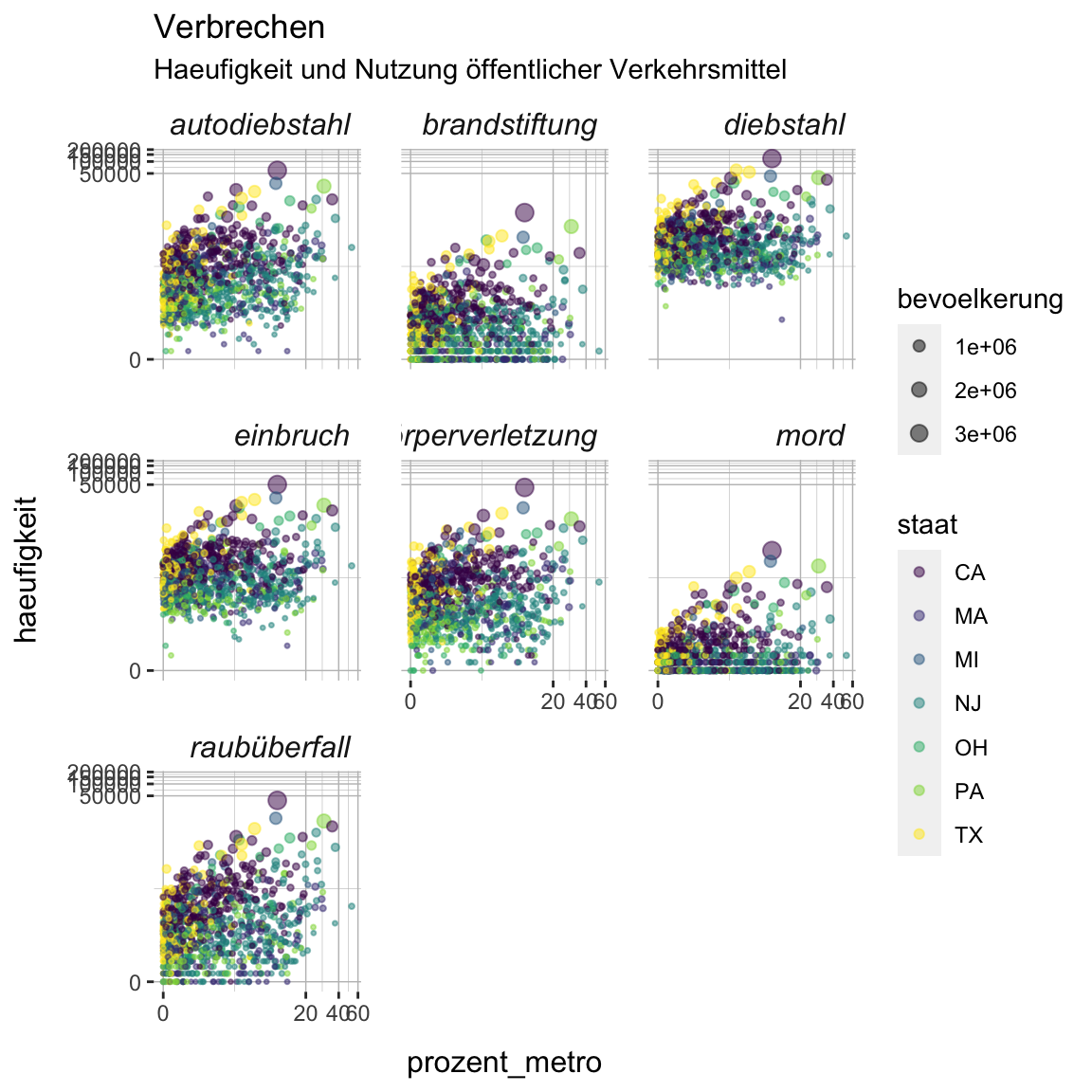
- Ok, sieht ganz ordentlich aus, oder? Kann man aber bestimmt noch verbessern. Go explore!
G - Bilddateien
Es ist an der Zeit euren Plot als eine Bilddatei zu speichern. Kreiere dafür zunächst mit dem Explorer (Windows) oder Finder (Mac) in deinem Projektordner einen neuen Ordner namens
3_Figures.Verwende nun
ggsaveum deinen letztenverbrechen_ggplot als eine.pdf-Datei unter dem Namenverbrechen.pdfzu speichern. Danach solltest du deinen Plot im Ordner3_Figuresfinden. Schaue nach und öffne die Datei.
ggsave(filename = "3_Figures/verbrechen.pdf",
device = "pdf",
plot = verbrechen_gg,
width = 4,
height = 4,
units = "in")ggsave(filename = "3_Figures/verbrechen.pdf",
device = "pdf",
plot = verbrechen_gg,
width = 4,
height = 4,
units = "in")- Probiere ein paar Sachen aus:
- Verändere
widthundheightin derggsave()Funktion. - Speichere ein
.pnganstatt eines.pdfindem dufilenameunddeviceentsprechend anpasst.
X - Challenges: Multiple Plots
In diesem Abschnitt kombinierst du mit dem patchwork Paket (nicht vergessen zu laden) multiple Plots zu einem einzelnen Plot.
Kreiere 3 verschiedene Plots, die jeweils
haeufigkeitengegen eine andere Variable im Datensatz plotten. Für eine bessere Übersicht verzichte erstmal auffacets. Nenne die 3 Plotsverbrechen_a,verbrechen_b, undverbrechen_c.Stelle alle 3 Plots nebeneinander mit
verbrechen_a + verbrechen_b + verbrechen_c.Stelle den 3. Plot unter die ersten beiden mit
verbrechen_a + verbrechen_b / verbrechen_c.Ändere das
themealler drei Plots gleichzeitig zutheme_void()mit dem&-Operator.Speichere deinen Plot als
.pdfmitggsave().
Beispiele
library(tidyverse)
# Scatterplot mit Hubraum und Meilen pro Gallone
ggplot(data = mpg,
mapping = aes(x = displ, y = hwy)) +
geom_point()
# Speichere den Plot
mein_plot <- ggplot(data = mpg,
mapping = aes(x = displ, y = hwy)) +
geom_point()
# Plotte den Plot
mein_plot
# Facets ------------
# Kreiere Facetten nach Klasse
mein_plot <- mein_plot +
facet_wrap(~class)
# plot
mein_plot
# Ändere themes ------------
# Ändere die Hintergrundfarbe
mein_plot +
theme(
panel.background = element_rect(fill='green')
)
# Ändere die Rasterlinien
mein_plot +
theme(
panel.grid.major = element_line(color = 'red', size = 2),
panel.grid.minor = element_line(color = 'blue', size = 1)
)
# Ändere den Überschriftenhintergrund
mein_plot +
theme(
strip.background = element_rect(fill = 'blue'),
strip.text = element_text(face = 'bold', size = 12)
)
# Ändere die Achsenbeschriftungen
mein_plot +
theme(
axis.title.y = element_text(size = 12, margin = margin(r = 10)),
axis.title.x = element_text(size = 12, margin = margin(t = 10))
)
# Ändere die Panelabstände
mein_plot +
theme(
panel.spacing = unit(2, "lines")
)
# Speichere themes ------------
# Kreiere theme
mein_theme <- theme(
panel.background = element_rect(fill='green'),
panel.grid.major = element_line(color = 'red', size = 2),
panel.grid.minor = element_line(color = 'blue', size = 1),
strip.background = element_rect(fill = 'blue'),
strip.text = element_text(face = 'bold', size = 12),
strip.background = element_rect(fill = 'blue'),
strip.text = element_text(face = 'bold', size = 12),
axis.title.y = element_text(size = 12, margin = margin(r = 10)),
axis.title.x = element_text(size = 12, margin = margin(t = 10)),
panel.spacing = unit(2, "lines")
)
# Wende theme an (keine Klammern)
mein_plot + mein_theme
# Skalierung ------------
# Ändere die x-Achsenskalierung
mein_plot + scale_x_continuous(limits = c(0, 10))
# Ändere die Farbskalierung
ggplot(data = mpg,
mapping = aes(x = displ, y = hwy,
color = class)) +
geom_point() +
scale_color_manual(values = viridis(7))
# Kreiere Bilddateien ------------
# Kreiere ein pdf
ggsave(filename = "mein_plot_name",
plot = mein_plot,
device = "pdf",
path = 'plotting_folder',
width = 4,
height = 4,
units = "in")Datensätze
| Datei | Zeilen | Spalten |
|---|---|---|
| verbrechen.csv | 7497 | 12 |
Der verbrechen Datensatz ist ein Ausschnitt aus dem “Communities and Crime Unnormalized Data Set” des “UCI Machine Learning Repository”.
Variablenbeschreibungen
| Variable | Beschreibung |
|---|---|
| gemeinde | Name der Gemeinde |
| staat | Kürzel des US Staats |
| bevoelkerung | Bevölkerungs |
| bevoelkerung_dichte | Dichte der Bevölkerungs |
| haushalt_groesse | Durchschnittliche Haushaltsgrösse |
| median_einkommen | Median Einkommen |
| prozent_pension | Prozent in Pension befindlicher Einwohner |
| prozent_armut | Prozent in Armut lebender Einwohner |
| prozent_arbeitslos | Prozent arbeitsloser Einwohner |
| prozent_metro | Prozent Metro-fahrender Einwohner |
| verbrechen | Art des Verbrechen |
| haeufigkeit | Häufigkeit des Verbrechens |
Funktionen
Paket
| Paket | Installation |
|---|---|
tidyverse |
install.packages("tidyverse") |
viridis |
install.packages("viridis") |
patchwork |
install.packages("patchwork") |
Funktionen
facets
| Function | Package | Description |
|---|---|---|
facet_wrap() |
ggplot2 |
Kreiere Facetting mit automatischen Zeilenbrüchen |
facet_grid() |
ggplot2 |
Kreiere Facetting in Tabellenform |
themes
| Function | Package | Description |
|---|---|---|
theme() |
ggplot2 |
Ändere themes |
element_rect() |
ggplot2 |
Helferfunktion für Flächen |
element_line() |
ggplot2 |
Helferfunktion für Linien |
element_text() |
ggplot2 |
Helferfunktion für Text |
element_blank() |
ggplot2 |
Helferfunktion für das Entfernen von Elementen |
scales
| Function | Package | Description |
|---|---|---|
scale_x_*(), scale_y_*() |
ggplot2 |
Skaliert die x- und y-Achsen |
scale_size_*() |
ggplot2 |
Skaliert Grössen |
scale_color_*() |
ggplot2 |
Skaliert Farben |
scale_fill_*() |
ggplot2 |
Skaliert Füllfarben |
scale_alpha_*() |
ggplot2 |
Skaliert Transparenz |
