class: center, middle, inverse, title-slide # Machine Learning ### The R Bootcamp @ Erfurt<br/><a href='https://therbootcamp.github.io'>www.therbootcamp.com</a><br/><a href='https://twitter.com/therbootcamp'><span class="citation">@therbootcamp</span></a> ### June 2018 --- layout: true <div class="my-footer"><span> <a href="https://therbootcamp.github.io/"><font color="#7E7E7E">Erfurt, June 2018</font></a>                                           <a href="https://therbootcamp.github.io/"><font color="#646464">www.therbootcamp.com</font></a> </span></div> --- # What is machine learning? .pull-left6[ ### Algorithms autonomously learning from data. Given data, an algorithm tunes its *parameters* to match the data, understand how it works, and make predictions for what will occur in the future. <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/mldiagram_A.png" width="80%" style="display: block; margin: auto;" /> ] .pull-right4[ <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/machinelearningcartoon.png" width="70%" style="display: block; margin: auto;" /> ] --- # Everyone uses machine learning .pull-left6[ > ### Machine learning drives our algorithms for demand forecasting, product search ranking, product and deals recommendations, merchandising placements, fraud detection, translations, and much more. ~ Jeff Bezos, Amazon founder ] .pull-right4[ <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/mlexamples.png" width="100%" style="display: block; margin: auto;" /> ] --- # What is the basic machine learning process? <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/MLdiagram.png" width="90%" /> --- # Why do we separate training from prediction? .pull-left4[ Just because an algorithm can fit past (training) data well, does *not* necessarily mean that it will *predict* new data well. Anyone can come up with a model of *past* data (e.g.; stock performance, lottery winnings). Predicting future performance is much more difficult. > "An economist is an expert who will know tomorrow why the things he predicted yesterday didn't happen today." ~ Evan Esar ] .pull-right6[ <img src="https://raw.githubusercontent.com/therbootcamp/Erfurt_2018June/master/_sessions/_image/prediction_collage.png" width="80%" /> ] --- <br><br> <font size = 6>Can you come up with a model that will perfectly match past data but is worthless in predicting future data?</font><br><br> .pull-left45[ ### Past "Training" Data <br> | id|sex | age|fam_history |smoking | disease| |--:|:---|---:|:-----------|:-------|-------:| | 1|m | 45|No |FALSE | 0| | 2|m | 43|Yes |FALSE | 1| | 3|f | 40|Yes |FALSE | 1| | 4|m | 51|Yes |FALSE | 1| | 5|m | 44|No |TRUE | 0| ] .pull-right45[ ### Future "Test" Data <br> | id|sex | age|fam_history |smoking |disease | |--:|:---|---:|:-----------|:-------|:-------| | 91|m | 51|Yes |TRUE |? | | 92|f | 47|No |TRUE |? | | 93|m | 39|No |TRUE |? | | 94|f | 51|Yes |TRUE |? | | 95|f | 50|Yes |FALSE |? | ] --- ## Two types of prediction tasks .pull-left45[ <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/classification_task.png" width="100%" style="display: block; margin: auto;" /> ] .pull-right45[ <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/regression_task.png" width="100%" style="display: block; margin: auto;" /> ] --- ## What machine learning algorithms are there? .pull-left55[ There are thousands of machine learning algorithms from many different fields. - Computer vision, natural language processing, reinforcement learning... Wikipedia lists 57 *categories* (!) of machine learning algorithms <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/wikipediaml.png" width="80%" style="display: block; margin: auto;" /> ] .pull-right4[ <br><br> ### 3 Algorithims We will focus on 3 algorithms that apply to most ML tasks: | Algorithm|Complexity| |:------|:----| | Decision Trees| Low | | Regression| Low / Medium | | Random Forests| High | ] --- ## How do you fit and evaluate ML models in R? .pull-left45[ Answer: Pretty much the same way you fit standard statistical models. Install the package, load, and find the main fitting functions. ```r # Install the glmnet package install.packages("glmnet") # Load glmnet library(glmnet) # Look at help menu ?glmnet ``` <b>Important!</b> Look at the help file for each function! Some functions will use the standard `FUN(formula, data)` arguments, but others (like `glmnet()`) require other arguments, like `x, y` (numeric matrices). ] .pull-right5[ ```r # Help file for glmnet ?glmnet ``` <img src="https://raw.githubusercontent.com/therbootcamp/Erfurt_2018June/master/_sessions/_image/glmnet_help.jpg" width="80%" /> ] --- ## Regression .pull-left5[ In regression, the criterion is modeled as the weighted sum of predictors times *weights* `\(\beta_{1}\)`, `\(\beta_{2}\)` ### Loan Default: One could model the risk of defaulting on a loan as: `$$Risk = Age \times \beta_{age} + Income \times \beta_{income} + ...$$` Training a model means finding values of `\(\beta_{Age}\)` and `\(\beta_{Income}\)` that 'best' match the training data. <img src="https://raw.githubusercontent.com/therbootcamp/therbootcamp.github.io/master/_sessions/_image/regression.png" width="50%" style="display: block; margin: auto;" /> ] .pull-right5[ ### Standard regression with glm() The `glm()` function in the base stats package performs standard regression ```r glm_mod <- glm(formula = happiness ~ ., data = baselers) ``` ### Regularised regression with glmnet() To perform regularised regression, which tries to reduce overfitting by penalising large coefficients, use the `glmnet()` package: ```r install.packages("glmnet") library("glmnet") net_mod <- glmnet(x, # Numeric features y, # Response alpha, # mixing parameter) ``` ] --- ## Decision Trees .pull-left45[ In decision trees, the criterion is modeled as a sequence of logical Yes or No questions. ### Loan Default: 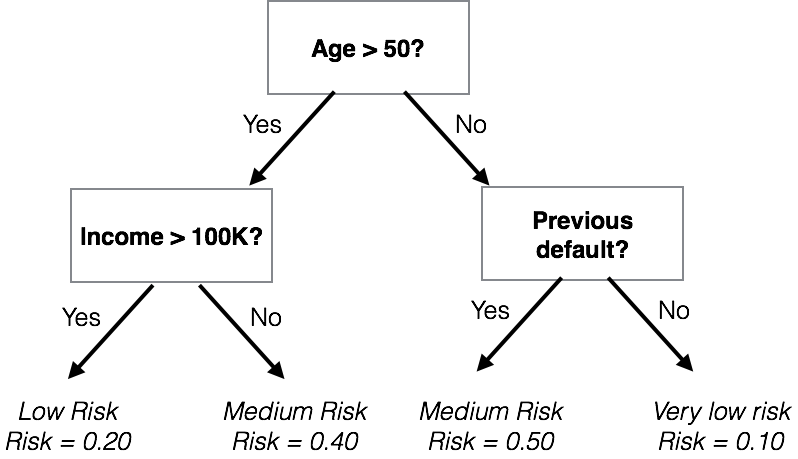<!-- --> ] .pull-right5[ ### Decision trees with rpart Create decision trees with `rpart` ```r install.packages("rpart") library(rpart) # Train rpart model loan_rpart_mod <- rpart(formula, data, method = "class", rpart.control) ``` ### Fast-and-frugal trees with FFTrees Create very simple fast-and-frugal decision trees with `FFTrees` ```r install.packages("FFTrees") library(FFTrees) loan_FFTrees_mod <- FFTrees(formula, data, max.levels, goal) ``` ] --- ## Ensemble decision trees .pull-left5[ A [Random Forest](https://en.wikipedia.org/wiki/Random_forest) is a collection of many (hundreds, thousands) of decision trees that use different features <div class="figure"> <img src="https://raw.githubusercontent.com/therbootcamp/Erfurt_2018June/master/_sessions/_image/randomforest_diagram.png" alt="<font size=3><a href='https://medium.com/@williamkoehrsen'>Sourcemedium.com</a></font>" width="90%" /> <p class="caption"><font size=3><a href='https://medium.com/@williamkoehrsen'>Sourcemedium.com</a></font></p> </div> ] .pull-right5[ Create a random forest using the `randomForest` package ```r install.packages("randomForest") library(randomForest) # Create a randomForest model randomForest(formula = y ~., # Formula data = data_train, # Training data ntree, mtry) # Tuning parameters ``` Here are some of the tuning parameters |Parameter | Description| |:-------|:-------| |`ntree`|Number of trees in forest| |`mtry`|Number of variables randomly selected at splits| ] --- ## Optimizing model parameters with cross validation .pull-left45[ Most machine learning models have two types of parameters, *raw parameters* that dictate how an individual model makes predictions, and *tuning parameters* that determine how those raw parameters are calculated. |Model| Raw parameters|Tuning parameters| |:------|:------|:------| |Decision Trees|Nodes, splits, decisions |Minimum number of cases in each node| |Regularised regression |Model coefficients | Coefficient penalty term| To determine 'optimal' tuning parameters, which maximize prediction performance, techniques such as cross validation are often used. ] .pull-right5[ ### Cross Validation <img src="https://raw.githubusercontent.com/therbootcamp/Erfurt_2018June/master/_sessions/_image/crossvalidation.jpg" width="80%" style="display: block; margin: auto;" /> 0) Select *tuning parameters* 1) Split the training set into K "folds" 2) Use K - 1 folds for training, and 1 fold for testing. 3) Repeat K times. 4) Average the K testing performances ] --- .pull-left55[ # Caret Caret stands for <b>C</b>lassification <b>A</b>nd <b>RE</b>gression <b>T</b>raining. `caret` is a 'wrapper' packages that automates much of the the machine learning process. Do very complex machine learning tasks with a few simple functions Use any of hundreds of different ML algorithms by changing one "string' (not line!) to use a different model ```r library(caret) train(..., method = "lm") # Regression! train(..., method = "rf") # Random forests! train(..., method = "ada") # Boosted trees ``` Knows each model's tuning parameters and chooses the best ones for your data using cross validation (or other method). ] .pull-right4[ <br><br><br> <div class="figure" style="text-align: center"> <img src="https://3qeqpr26caki16dnhd19sv6by6v-wpengine.netdna-ssl.com/wp-content/uploads/2014/09/Caret-package-in-R.png" alt="The almighty Caret!" width="90%" /> <p class="caption">The almighty Caret!</p> </div> <img src="https://upload.wikimedia.org/wikipedia/commons/1/1c/K-fold_cross_validation_EN.jpg" width="100%" style="display: block; margin: auto;" /> ] --- .pull-left5[ # Caret As always, you can install `caret` from CRAN ```r # Install caret install.packages("caret") # Load the caret package library("caret") ``` Once you've installed `caret`, look at the vignette for a nice overview of the package ```r # Open the main package vignette vignette("caret") ``` Today we will go over the main functions in the package ] .pull-right45[ ### Caret Vignettes The `caret` package has some of the *best* documentation (vignettes) you'll ever see. <img src="caret_vignette.jpg" width="90%" /> ] --- .pull-left5[ # Caret Here are the main functions we will cover in the `caret` package | Function| Purpose| |--------|----------| | `createDataPartition()` | Split data into different partitions| | `trainControl()` | Determine how training (in general) will be done| | `train()` | Specify a model and find *best* parameters| | `varImp()` | Determine variable importance | | `predict()` | Predict values for new data| | `postResample()` | Evaluate prediction performance| ] .pull-right45[ ### Caret Vignettes The `caret` package has some of the *best* documentation (vignettes) you'll ever see. <img src="caret_vignette.jpg" width="90%" /> ] --- .pull-left6[ ### createDataPartition() Use `createDataPartition()` to split a dataset into separate partitions. Useful to split a large dataset into separate training and test data ```r data <- baselers %>% drop_na # Drop missing cases from baselers # Get training cases train_v <- createDataPartition(y = data$income, #crit times = 1, p = .5)$Resample1 # Vector of training cases train_v[1:10] ``` ``` ## [1] 1 3 7 10 14 15 16 19 20 21 ``` ```r # Training Data baselers_train <- data %>% slice(train_v) # Testing Data baselers_test <- data %>% slice(-train_v) ``` ] .pull-right35[ ### Training and Test ```r ### Training data dim(baselers_train) ``` ``` ## [1] 3072 20 ``` ```r baselers_train %>% slice(1:5) %>% select(1:3) ``` ``` ## # A tibble: 5 x 3 ## id sex age ## <int> <chr> <dbl> ## 1 1 male 44 ## 2 4 male 27 ## 3 9 male 43 ## 4 12 male 31 ## 5 18 female 62 ``` ```r ### Testing data dim(baselers_test) ``` ``` ## [1] 3068 20 ``` ] --- .pull-left55[ ### trainControl() Use `trainControl()` to define how `carat` should select the best parameters for any ML model (that you will specify later with `train()`) Many methods are available in the `method` argument, look at the help menu with `?trainControl` for additional details ```r # Define how caraet should # select best model parameters ctrl <- trainControl(method = "repeatedcv", number = 10, # 10 folds repeats = 2) # Repeat 2 times ``` ### trainControl methods |method|Description| |:----|:----| |`"repeatedcv"` | Repeated cross-validation| |`"LOOCV"`| Leave one out cross-validation| |`"none"` | Fit one model with default parameters | ] .pull-right4[ <br><br><br><br> ### Cross Validation <!-- --> ] --- .pull-left55[ ### train() Use `train()` to fit **any** of over 280 models **and** get best parameters ```r rpart_train <- train(form = income ~ ., data = baselers_train, method = "rpart", # Model! trControl = ctrl) ``` |Parameter|Description| |:-----|:----| |`form`|Formula specifying criterion| |`data`|Training data| |`method`| Model| |`trControl`| Control parameters| ] .pull-right4[ See all >280 models on the [Caret Documentation Page](http://topepo.github.io/caret/available-models.html) <img src="caret_models.jpg" width="1699" /> ] --- ### train() .pull-left55[ For classification tasks, make sure your criterion is a factor. For regression tasks, make sure it is numeric ```r # Diagnosis is currently coded as 0, 1 heartdisease$diagnosis[1:10] # Will be a regression model reg_mod <- train(form = diagnosis ~ ., data = heartdisease, method = "rpart") ``` <font color='red' size = 3>Warning messages: 1: In train.default(x, y, weights = w, ...) : You are trying to do regression and your outcome only has two possible values Are you trying to do classification? If so, use a 2 level factor as your outcome column.</font> ```r # Will be a classification model class_mod <- train(form = factor(diagnosis) ~ ., data = heartdisease, method = "rpart") ``` ] .pull-right4[ [Caret Documentation Page](http://topepo.github.io/caret/available-models.html) <img src="caret_models.jpg" width="1699" /> ] --- ### train() Print the result of `train()` to obtain overall results ```r rpart_train ``` ``` ## CART ## ## 3072 samples ## 19 predictor ## ## No pre-processing ## Resampling: Cross-Validated (10 fold, repeated 2 times) ## Summary of sample sizes: 2764, 2764, 2765, 2765, 2765, 2766, ... ## Resampling results across tuning parameters: ## ## cp RMSE Rsquared MAE ## 0.0624 1481 0.7148 1193 ## 0.1142 1761 0.5958 1416 ## 0.5631 2327 0.5400 1873 ## ## RMSE was used to select the optimal model using the smallest value. ## The final value used for the model was cp = 0.0624. ``` --- .pull-left4[ ### train() Explore your `train` Object ```r # Best tuning parameters rpart_train$bestTune ``` ``` ## cp ## 1 0.0624 ``` ```r # Show the final model rpart_train$finalModel ``` ``` ## n= 3072 ## ## node), split, n, deviance, yval ## * denotes terminal node ## ## 1) root 3072 2.362e+10 7541 ## 2) age< 46.5 1814 4.717e+09 5808 * ## 3) age>=46.5 1258 5.604e+09 10040 ## 6) age< 64.5 852 1.773e+09 9029 * ## 7) age>=64.5 406 1.132e+09 12160 * ``` ] .pull-right55[ ```r # Plot final model plot(rpart_train$finalModel) text(rpart_train$finalModel) ``` <img src="MachineLearning_files/figure-html/unnamed-chunk-46-1.png" style="display: block; margin: auto;" /> ] --- .pull-left5[ ### varImp() Use `varImp()` to extract **variable importance** from a model Result will be be a model-specific method indicaating how important each variable was in predicting the criterion. ```r varImp(rpart_train) ``` ``` ## rpart variable importance ## ## only 20 most important variables shown (out of 24) ## ## Overall ## age 100.000 ## food 59.720 ## happiness 1.115 ## fitness 0.644 ## datause 0.602 ## id 0.231 ## tattoos 0.211 ## educationSEK_II 0.000 ## alcohol 0.000 ## consultations 0.000 ## `confessionevangelical-reformed` 0.000 ## height 0.000 ## children 0.000 ## confessionconfessionless 0.000 ## rhine 0.000 ## confessionother 0.000 ## hiking 0.000 ## sexmale 0.000 ## fasnachtyes 0.000 ## weight 0.000 ``` ] .pull-right45[ ```r # Plot variable importance plot(varImp(rpart_train)) ``` <!-- --> ] --- .pull-left5[ ## predict(), postResample() Test a models prediction performance with `predict()` ```r # Get predictions based on best bas_pred <- predict(object = rpart_train, newdata = baselers_test) # Result is a vector of predictions # for each row in newdata bas_pred[1:5] ``` ``` ## 1 2 3 4 5 ## 12162 9029 12162 5808 5808 ``` Then summarise overall performance with `postResample()` ```r # Assess performance with postResample() postResample(pred = bas_pred, obs = baselers_test$income) ``` ``` ## RMSE Rsquared MAE ## 1583.4110 0.6516 1270.2859 ``` ] .pull-right45[ ### Plot predictions vs Truth ```r # Plot predictions versus truth end <- tibble(pred = bas_pred, obs = baselers_test$income) ggplot(data = end, aes(x = pred, y = obs)) + geom_point(alpha = .1) + labs(title = "Rpart Performance", x = "Predictions", y = 'Truth') + theme_bw() + geom_smooth(method = "lm") ``` <img src="MachineLearning_files/figure-html/unnamed-chunk-51-1.png" style="display: block; margin: auto;" /> ] --- .pull-left5[ ## Recap - ML steps with caret Step 0: Create training and test data (if necessary) ```r train_v <- createDataPartition(y, times, p) data_train <- data %>% slice(train_v) data_test <- data %>% slice(-train_v) ``` Step 1: Define control parameters ```r ctl <- trainControl(method = "repeatedcv", number = 10, repeats = 2) ``` Step 2: Train model ```r rpart_train <- train(form = income ~ ., data = data_train, method = "rpart", trControl = ctl) ``` ] .pull-right45[ <br><br><br> Step 3: Explore ```r rpart_train # Print object varImp(rpart_train) # Var importance rpart_train$finalModel # Final model ``` Step 4: Predict ```r my_pred <- predict(object = rpart_train, newdata = data_test) ``` Step 4: Evaluate ```r postResample(pred = bas_pred, obs = baselers_test$income) ``` ] --- <br><br> .pull-left5[ # Caret There are *many* other great features of caret we haven't touched - Use the `preProcess()` function to process your data (Imputing (replacing) missing values and transforming predictors) - Add your own custom model Be sure to check out the **excellent** documentation site to learn all the details ] .pull-right45[ ### http://topepo.github.io/caret/index.html <img src="caret_package_md.jpg" width="2251" /> ] --- # Questions? <br><br><br> # [Machine Learning Practical](https://therbootcamp.github.io/Erfurt_2018June/_sessions/D2S2_MachineLearning/MachineLearning_practical.html) ---