Markdown
|
Reporting mit R The R Bootcamp |

|

adapted from Airbnb.com
Überblick
In diesem Practical machst du deine ersten Schritte mit R Markdown.
Am Ende des Practicals wirst du wissen wie man:
- Text in das Dokument einfügt.
- Inline Code im Text verwendet.
- Chunks erstellt und einstellt.
Aufgaben
A - Setup
Öffne dein
TheRBootcampR Projekt. Es sollte die Ordner1_Data,2_Assets, und3_Markdownenthalten.Öffne ein neues RMarkdown Skript und wähle das Template “HTML” aus (siehe screenshot).
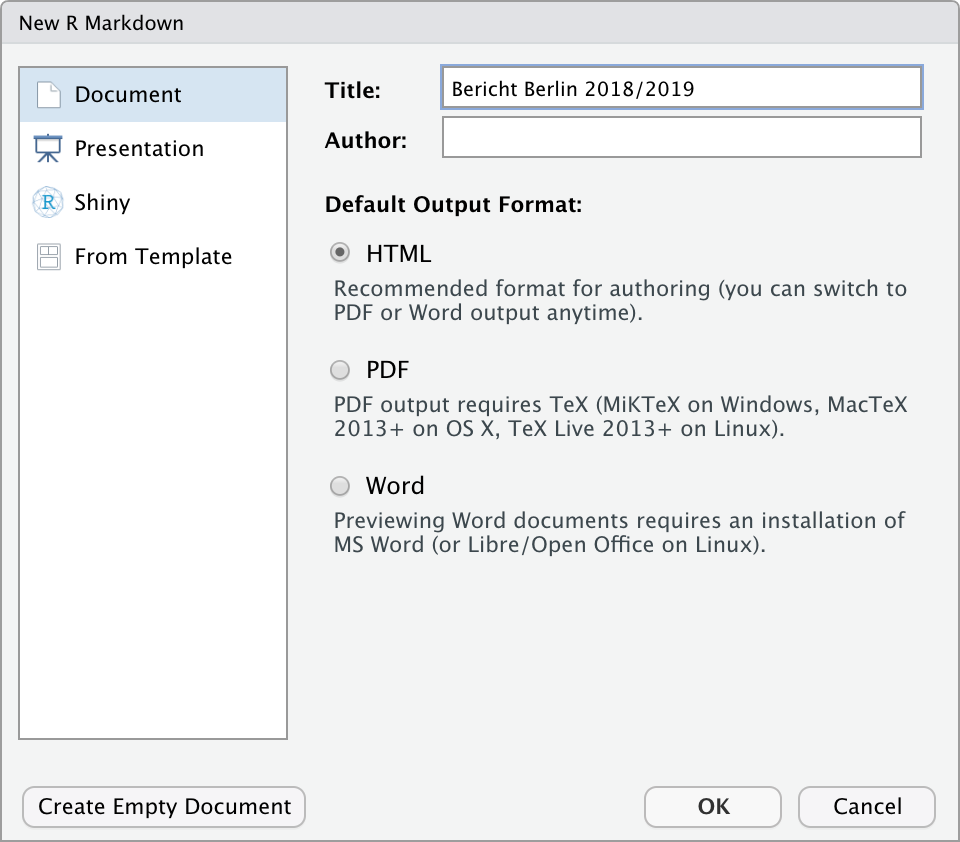
Trage als Titel
Bericht Berlin 2018/2019ein.Speichere das neue Markdown Skript unter dem Namen
Airbnb_level_one.Rmdim3_MarkdownOrdner ab.Lösche alles unterhalb des
setupCode Chunks.Lade die Pakete
tidyverseundlubridateimsetupChunk.
# Lade Pakete
library(tidyverse)
library(lubridate)- Lade den
AirbnbDatensatz mitread_csv()ebenfalls imsetupChunk mit dem Code unten.
# Lade Airbnb Datensatz
Airbnb <- read_csv("../1_Data/Airbnb.csv")- Verwende den Code unten um nur die beiden Jahre
2018und2019aus den Daten auszuwählen und ein neues ObjektAirbnb_1819zu erstellen.
# Wähle Jahre 2018 und 2019 aus
Airbnb_1819 <- Airbnb %>%
filter(Erstellungsdatum > "2018-01-01",
Erstellungsdatum < "2019-12-31")B - Präambel
- Unter den
setupChunk, setze eine Überschrift auf drittem Level (###) mit TitelPräambel.
### Präambel- Nun setze unter die Überschrift den folgenden Text.
Dieser Bericht analysiert Veränderungen in den Neueinstellungen und den Preisen von Airbnb Objekten in Berlin, Deutschland. Er wurde zum Zwecke der Übung auf Basis öffentlich verfügbarer Daten erstellt und repräsentiert einzig die Position der Autoren. Es besteht keine Beziehung zu Airbnb. Knittedas Dokument. Sieht alles in Ordnung aus?
C - Neueinstellungen: Text Teil 1
- Setze eine weitere Überschrift auf dritter Ebene (
###) mit TitelNeueinstellungenund darunter eine Überschrift auf vierter Ebene (####) mit dem TitelEntwicklung.
### Neueinstellungen
#### Entwicklung- Füge nun diesen Text ein. Er enthält einige Werte, die du gleich durch inline Code ersetzen wirst.
Seit 02.01.2018 wurden in Berlin 5007 Airbnb Wohnungen eingestellt. Von diesen Wohnungn weisen aktuell 73% Verfügbarkeiten von durchschnittlich 47.5 Tagen für die nächsten 3 Monate auf.
Einstellungen von Airbnb Wohnungen haben im letzten Jahr stark zugenommen. Im Jahr 2019 wurden insgesamt 3274 neue Wohnungen eingestellt, wohingegend im Jahr 2018 nur 1733 Wohnungen eingestellt wurden. Dies entspricht einem Zuwachs von 89%.- Tausche zunächst das Datum an zweiter Stelle im Text durch den folgenden inline Code aus. Nicht vergessen, der Code muss zwischen zwei Gravis (`r Code`) gesetzt werden. Knitte das Dokument.
r min(Airbnb_1819$Erstellungsdatum)- Jetzt sollte der Text ein Datum enthalten, welches aber noch nicht ganz richtig formatiert ist. Hier hilft die
strftime()Funktion. Versuche mit dem folgenden inline Code das Datum in das richtige Format zu bringen.
r strftime(min(Airbnb_1819$Erstellungsdatum), "%d.%m.%Y")Als nächstes ersetze die Anzahl der Wohnungen durch
nrow(Airbnb_1819). Nicht dasram Anfang vergessen!Ersetze nun Prozentsatz der Wohnungen durch
round(mean(Airbnb_1819$Verfügbarkeit_90Tage > 0) * 100)und die durchschnittliche Verfügbarkeit durchround(mean(Airbnb_1819$Verfügbarkeit_90Tage[Airbnb_1819$Verfügbarkeit_90Tage>0]),1). Jetzt sollten alle Zahlen des ersten Absatz durch Code ersetzt worden sein. Überprüfe ob alles stimmt.Im nächsten Absatz ersetze die ersten beiden Zahlen durch
n_2019 <- sum(year(Airbnb_1819$Erstellungsdatum) == 2019); n_2019undn_2018 <- sum(year(Airbnb_1819$Erstellungsdatum) == 2018); n_2018. In diesen beiden Fällen siehst du, dass auch Zuweisungen in inline Code möglich sind.Ersetze nun den wert des Zuwachses am Ende des Absatzes durch
(round(n_2019/n_2018, 2) - 1)*100, was, wie du siehst, auf die beiden zuvor im inline Code definierten Objekte zurückgreift. Knitte das Dokument und überprüfe, ob nun alle Zahlen einwandfrei wiedergegeben werden.Zuletzt verwende ** um den gesamten zweiten Absatz fett zu setzen. Setze hierfür einmal die zwei Asteriske vor das erste und nach dem letzten Wort des Absatzes. Nun alles wie im Zieldokument?
D - Neueinstellungen: Grafik Teil 1
- Erstelle einen neuen Code Chunk. Einen Chunk erstellst du mit zunächst drei Gravis ```, dann direkt danach in der selben Zeile
{r}und anschliessend nocheinmal drei Ticks in einer Zeile darunter. Wie in der Abbildung unten sollte sich der Hintergrund automatisch grau einfärben.

- Kopiere in den Chunk, d.h., zwischen die zwei Zeilen mit den drei Gravis/Ticks, den Code unten, welcher eine erste Version der ersten Grafik im Bericht generiert.
# Plotte Häufigkeiten
ggplot(Airbnb_1819 %>%
group_by(Jahr = year(Erstellungsdatum),
Monat_tmp = month(Erstellungsdatum)) %>%
summarize(Monat = as_factor(paste(first(Jahr), first(Monat_tmp), sep = '-')),
Wohnungen = n()),
aes(x = Monat, y = Wohnungen, fill = Jahr)) +
geom_bar(stat = 'identity', position = 'dodge') +
theme(legend.position = 'none',
axis.text.x = element_text(angle = 45, hjust = 1)) E - Chunk-Optionen
- Aktuell zeigt dein “geknittetes” Dokument sowohl den Code für den Plot als auch den Plot selbst an. Das Dokument soll aber nur den Plot zeigen. Ergänze in den Chunk Optionen, d.h., innerhalb der geschwungenen Klammern nach dem
r,echo = FALSE. Danach knitte das Dokument nocheinmal.

Das Dokument sollte nun den Code im Chunk nicht mehr anzeigen. Mache nun dieses Setting rückgängig, d.h., lösche
echo = FALSE, es gibt nämlich einen zweiten Weg diesen und alle zukünftigen Code Chunks zu verstecken. Knitte das Dokument nachdem du dasecho = FALSEentfernt hast.Gehe nun zum Setup-Chunk ganz am Anfang es Dokuments (unter dem YAML header). Dort siehst du folgende Code Zeile
knitr::opts_chunk$set(echo = TRUE), die aktuell impliziert, dass alle Code Chunks per default angezeigt werden. Setze nun hierecho = FALSEund knitte das Dokument. Der Code Chunk sollte nun wieder versteckt sein. Behalte diese Einstellung auch für die weiteren Sessions bei.Ergänze nun zusätzlich in den allgemeinen Chunk-Optionen
message = FALSEundwarning = FALSE, was vollständig verhindert, dass Messages oder Warnings im Bericht auftauchen. Die finalen Settings sollten nun so aussehen.
knitr::opts_chunk$set(echo = FALSE, message = FALSE, warning = FALSE)F - Neueinstellungen: Text Teil 2
Setze unten im Script eine weitere Überschrift auf vierter Ebene (
####) mit dem TitelStadtteile.Unter die Überschrift setze den folgenden Text.
Neueinstellungen fallen nach wie vor sehr unterschiedlich in den Bezirken aus. Die meisten Neueinstellungen im Jahr 2019 gab es in Friedrichshain-Kreuzberg, die wenigsten in Marzahn - Hellersdorf.
Die grössten Veränderungen gab es in Marzahn - Hellersdorf und Treptow - Köpenick. In Marzahn - Hellersdorf schrumpften die Neueinstellungen um -13.3%, in Treptow - Köpenick wuchsen die Neueinstellungen um 137.8%.- Vor den Text setze den folgenden Chunk, welcher die Häufigkeiten der Neueinstellungen über die Stadtteile berechnet und im Objekt
stadtteilespeichert.
# Berechne Häufigkeiten über die Bezirke
stadtteile <- Airbnb_1819 %>%
group_by(Stadtteil,
Jahr = year(Erstellungsdatum)) %>%
summarize(Wohnungen = n()) %>%
ungroup() %>%
arrange(desc(Jahr), Wohnungen) %>%
mutate(Stadtteil = as_factor(Stadtteil))Ersetze nun die die zwei im ersten Paragraph erwähnten Stadtteile durch
stadtteile %>% filter(Jahr == 2019) %>% pull(Stadtteil) %>% last()undstadtteile %>% filter(Jahr == 2019) %>% pull(Stadtteil) %>% first(). Knitte das Dokument und schaue, ob die richtigen Namen eingesetzt wurden.Kreiere einen neuen Chunk zwischen den beiden Absätzen mit dem folgenden Code, welcher einige Objekte erstellt, die die inline Ergänzungen im darauf folgenden Absatz erleichtern werden.
# Veränderung über die Stadtteile
veränderung = stadtteile %>%
group_by(Stadtteil) %>%
summarize(veränderung = (100 * (Wohnungen[Jahr == 2019]/Wohnungen[Jahr == 2018] - 1)) %>% round(1))
# Geringsten Veränderung
min_veränderung = veränderung %>%
slice(which.min(veränderung)) %>%
pull(veränderung)
# Stadteil mit der geringsten Veränderung
min_stadtteil = veränderung %>%
slice(which.min(veränderung)) %>%
pull(Stadtteil)
# Grösste Veränderung
max_veränderung = veränderung %>%
slice(which.max(veränderung)) %>%
pull(veränderung)
# Stadteil mit der grössten Veränderung
max_stadtteil = veränderung %>%
slice(which.max(veränderung)) %>%
pull(Stadtteil)Ersetze die ersten beiden Stadtteil-Nennungen in beiden Sätzen durch
min_stadtteilundmax_stadtteilund knitte das Dokument. Passt alles?Ersetze nun
schrumpftenundwuchsendurchifelse(min_veränderung > 0, "wuchsen", "schrumpften")undifelse(max_veränderung > 0, "wuchsen", "schrumpften"). Die beiden Codestücke können dann selbst entscheiden, ob die Veränderung eine positive oder negative ist und das jeweils richtige Wort einsetzen.Abschliessend ersetze die beiden numerischen Werte durch
min_veränderungundmax_veränderung. Knitte das Dokument und überprüfe, ob alles in Ordnung ist.
G - Neueinstellungen: Grafik Teil 2
- Erstelle einen neuen Chunk mit dem folgenden Code für die zweite Grafik.
# Plotte Häufigkeieten der Stadtteile
ggplot(stadtteile,
aes(y = Stadtteil, x = Wohnungen, group = Jahr, fill = Jahr)) +
geom_bar(stat = 'identity', position = 'dodge') +
theme(legend.position = 'none') +
labs(y = '')- Knitte das Dokument. Der erste Teil ist hiermit abgeschlossen.
Datensatz
Der Airbnb.csv Datensatz enthält Zahlen zu 9868 Berliner Airbnbs
| Variable | Beschreibung |
|---|---|
| Preis | Preis pro Nacht |
| Erstellungsdatum | Eröffnungsdatum des Airbnbs |
| Unterkunftsart | Appartement, Loft, Haus, etc. |
| Schlafplätze | Anzahl Schlafplätze |
| Schlafzimmer | Anzahl Schlafzimmer |
| Badezimmer | Anzahl Badezimmer |
| Reinigungsgebühr | Reinigungsgebühr |
| Verfügbarkeit_90Tage | |
| Viertel | In welchem Viertel befindet sich das Airbnb |
| Stadtteil | In welchem Stadtteil befindet sich das Airbnb |
| Breitengrad | Breitengrad |
| Längengrad | Längengrad |
| Host_id | Host id |
| Host_seit | Erfahrung des Hosts |
| Host_antwortzeit | Host Antwortzeit |
| Host_antwortrate | Host Antwortrate |
| Host_superhost | Superhost Ja/Nein |
| Host_anzahl | Anzahl Gäste |
| Rating_gesamt | Gesamtrating |
| Rating_genauigkeit | Genauigkeitsrating |
| Rating_sauberkeit | Sauberkeitsrating |
| Rating_checkin | Checkinrating |
| Rating_kommunikation | Kommunikationsrating |
| Rating_lage | Lagerating |
| Rating_wertigkeit | Wertigkeitsrating |
| Küche | Küche vorhanden TRUE/FALSE |
| Wifi | WLAN vorhanden TRUE/FALSE |
| TV | TV vorhanden TRUE/FALSE |
| Kaffeemaschine | Kaffeemaschine vorhanden TRUE/FALSE |
| Geschirrspüler | Geschirrspüler vorhanden TRUE/FALSE |
| Terrasse_Balkon | Terrasse/Balkon vorhanden TRUE/FALSE |
| Badewanne | Badewanne vorhanden TRUE/FALSE |
| Check_in_24h | 24h Check-In vorhanden TRUE/FALSE |
Funktionen
Paket
| Paket | Installation |
|---|---|
tidyverse |
install.packages("tidyverse") |
lubridate |
install.packages("lubridate") |
Funktionen
| Funktion | Paket | Beschreibung |
|---|---|---|
strftime |
lubridate |
Formatierung von Daten |
ggplot |
ggplot |
Erstellen von Grafiken |
Materialien
- Allgemeiner Einstieg in RMarkdown.
- DIE Referenz für RMarkdown bis ins letzte Detail.
- Rmarkdown Dokumentation und Befehlsreferenz.